유니온-파인드 알고리즘은 우리가 알고 있는 수학적 집합(set)을 표현하는 기법입니다. 굉장히 자주 쓰이는 기법입니다. 유니온-파인드 알고리즘을 알아보기 전에 집합(set)에 대해서 먼저 알아보겠습니다.
고등학교 수학 시간에 배운 집합에서 서로 공통 원소가 없는 집합을 Disjoint Set 이라고 합니다. 이름 그대로 서로소 집합입니다. 집합을 구현하는 데는 벡터, 배열, 연결리스트를 이용할 수 있으나 가장 효율적인 트리 구조를 이용하여 표현하고, Union-Find 알고리즘에서도 트리 구조를 이용합니다.
유니온파인드 알고리즘은 Disjoint Set을 표현할 때 사용하는 알고리즘입니다. 이름 그대로 Union ( 합집합 ) , Find ( 어떤 집합에 속해있는지 )를 위한 알고리즘입니다. 기본적으로 트리 구조를 이용합니다.
-
Union(x, y)
: x가 속한 집합과 y가 속한 집합을 합친다.
-
Find(x)
: x가 속한 집합을 알려준다.
그럼 유니온파인드 알고리즘이 어떻게 집합을 트리 구조로 표현하는지 아래 그림을 통해 먼저 알아보겠습니다.
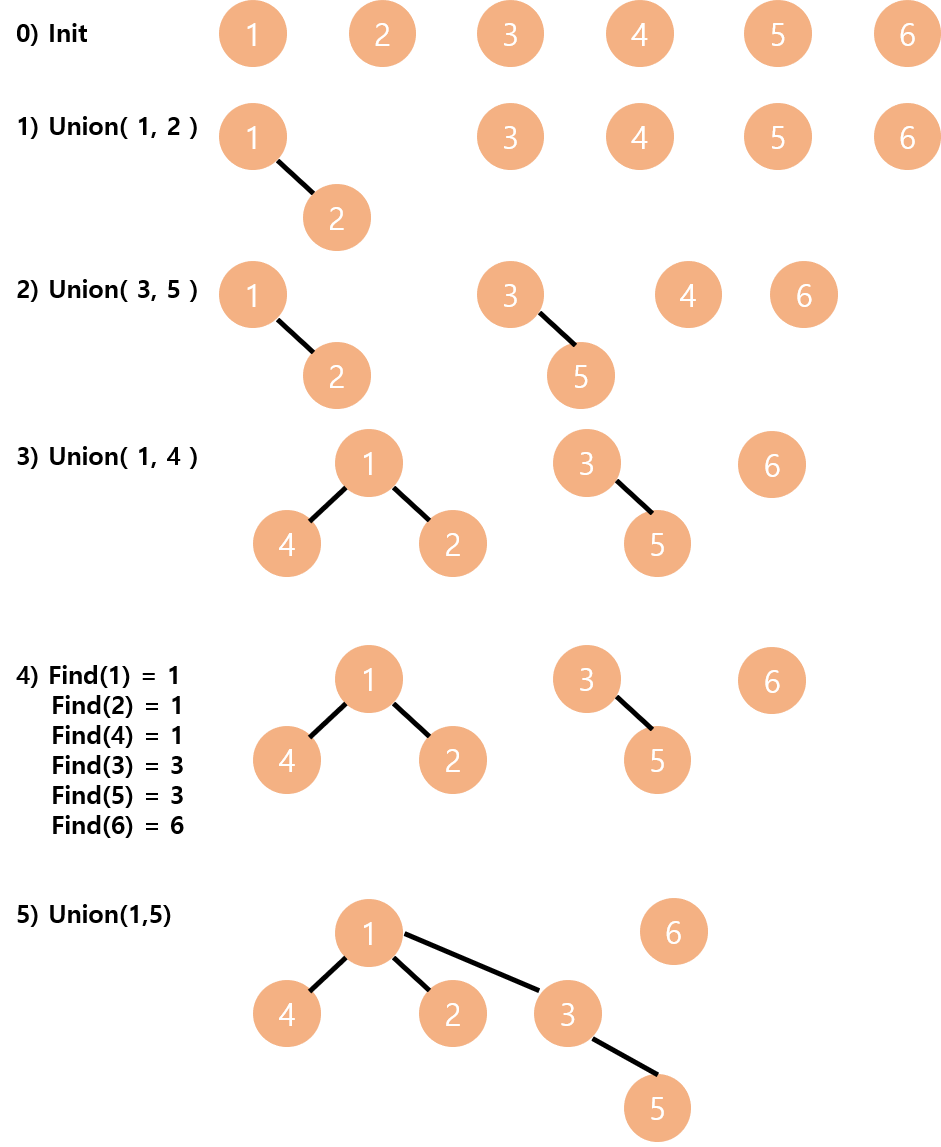
다음과 같이 1개의 원소가 들어가있는 6개의 집합이 있다고 가정해보겠습니다.
Union(1,2) 명령을 하면 1이 속한 집합과 2가 속한 집합을 합집합 해달라는 뜻이고 그림과 같이 트리 구조로 서로 이어줍니다.
Find 명령을 하면 속한 집합의 가장 루트 노드를 반환해줍니다.
-
parent 배열
x 의 부모 노드를 저장하는 배열입니다. 처음에는 모두 자기 자신만 포함되어있는 집합이기 때문에 자기 자신의 노드 번호를 셋팅해주면 됩니다. 자기 자신의 노드 번호가 저장된 노드는 그 집합의 루트 노드입니다.
-
find(x) 함수
x가 속한 집합의 루트 노드를 반환하는 함수입니다. 루트 노드는 자기 자신의 번호를 parent 배열에 저장하고 있기 때문에 재귀적으로 find 함수를 호출하며 루트 노드를 찾을 수 있습니다.
-
merge(x, y) 함수
x가 속한 집합과 y가 속한 집합을 합집합 해줍니다. 간단합니다. x가 속한 집합의 루트 노드와 y가 속한 집합의 루트 노드를 연결해주면 됩니다.
참고 : Union은 C 계열에서 키워드로 정의되어있어 보통 Union 대신에 함수 이름을 Merge로 설정합니다.
int parent[MAX]; // 각 집합의 루트 노드를 담고 있는 배열
int find(int node) {
if (node == parent[node])
return node;
return find(parent[node]);
}
void merge(int node1, int node2) {
int parentNode1 = find(node1);
int parentNode2 = find(node2);
if (parentNode1 == parentNode2)
return;
parent[parentNode1] = parentNode2;
return;
}Find 함수를 보면 루트 노드를 찾을 때까지 재귀적으로 탐색을 진행합니다. 즉, 트리의 높이가 작아지면 작아질수록 루트 노드를 탐색하는게 빨라집니다.
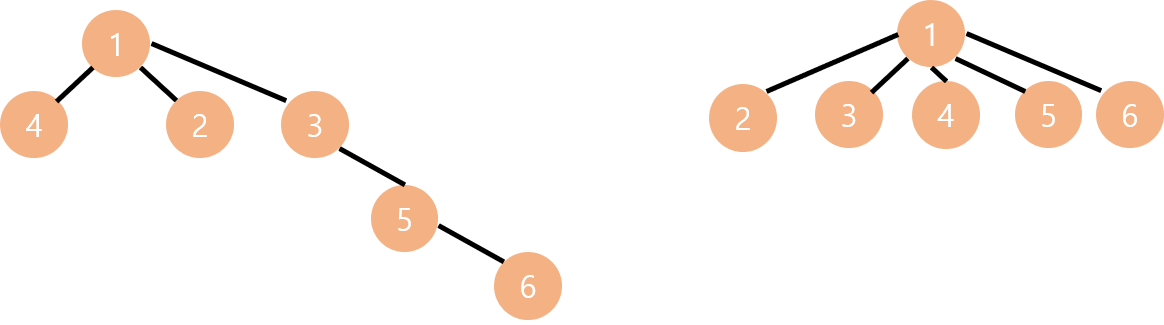
왼쪽 트리는 6번 노드의 루트 노드를 찾기 위해 5번 노드, 3번 노드, 1번 노드를 거쳐야합니다. 반면 오른쪽 트리는 6번 노드의 루트 노드를 찾기 위해 1번 노드만 거치면 됩니다. 이처럼 Find 함수는 트리의 높이에 따라 수행 시간이 결정되는 것을 알 수 있습니다.
// 수정 전
int find(int node) {
if (node == parent[node])
return node;
return find(parent[node]);
}
// 수정 후
int find(int node) {
if (node == parent[node])
return node;
return parent[node] = find(parent[node]);
}Find 함수를 조금만 수정하면 노드를 탐색해나가면서 노드들을 다 루트 노드와 직접적으로 연결시킬 수 있습니다.
이제 Union 함수도 최적화에 대해서 생각해봅시다.
void merge(int node1, int node2) {
int parentNode1 = find(node1);
int parentNode2 = find(node2);
if (parentNode1 == parentNode2)
return;
parent[parentNode1] = parentNode2;
return;
}지금 위의 코드를 보면 Union(x, y) 를 진행하면 x 집합의 루드 노드를 y 집합의 루트 노드로 변경해서 x 집합이 y 집합의 subSet으로 들어가는 것을 볼 수 있습니다.
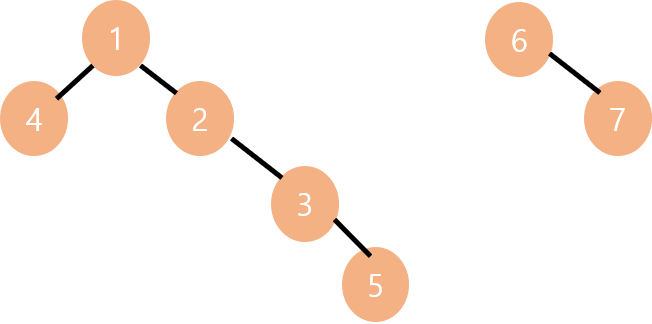
위의 그림에서 왼쪽 트리와 오른쪽 트리를 합치면 2가지 경우가 있습니다.
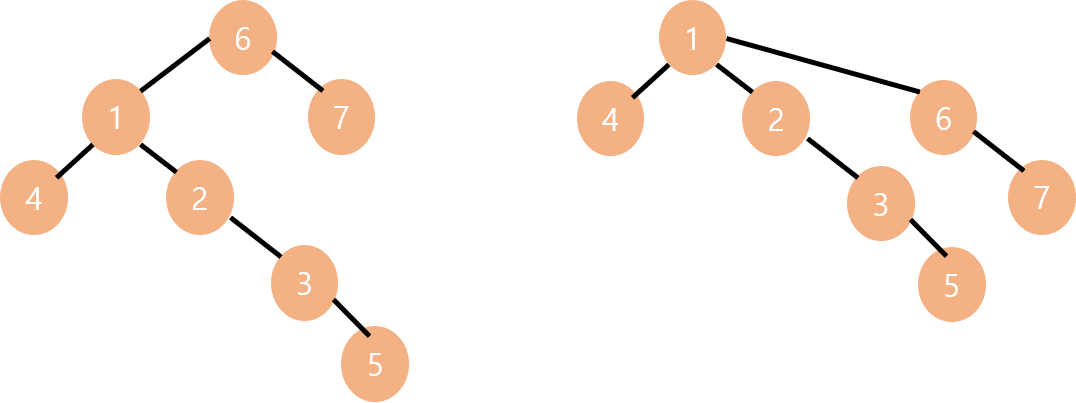
지금은 차이가 많이 없지만 노드의 수가 더 많은 트리를 더 작은 트리에 합치게 된다면 트리의 높이가 높아질 수 밖에 없습니다. 따라서 우리는 노드의 수가 더 적은 트리를 더 많은 트리에 합치면 Union 함수를 최적화 할 수 있습니다.
가장 간단한 방법은 트리의 Size를 따로 저장하는 Size 배열을 하나 더 선언해서 이용하는 것입니다.
void merge(int node1, int node2) {
int parentNode1 = find(node1);
int parentNode2 = find(node2);
if (parentNode1 == parentNode2)
return;
if (size[parentNode1] > size[paretNode2]) {
parent[parentNode2] = parentNode1;
size[parentNode1] += size[parentNode2];
}
else {
parent[parentNode1] = parentNode2;
size[parentNode2] += size[parentNode1];
}
return;
}Union-Find 알고리즘을 이용하면 Disjoint set 을 표현할 수 있고, 생각보다 자주 쓰이는 알고리즘입니다. Find와 Union 모두 최적화를 진행하는 법까지 정리해보았습니다.