KMP 알고리즘이란 문자열을 검색하는 알고리즘으로 우리가 이미 많이 쓰고 있는 알고리즘입니다. 우리가 흔히 Ctrl + F 를 누르고 웹 페이지나 문서에서 원하는 키워드를 찾는 작업도 KMP 알고리즘을 이용해서 이루어집니다.
문자열 검색이란 주어진 긴 문자열(H) 에서 문자열 (N)을 찾는 것을 말합니다.
그럼 어떻게 문자열 검색을 할 수 있을까요?? 단순하게 생각해보면 하나하나 다 비교해보면 됩니다.
"ABCDABCABACBABC" 에서 문자열 "ABC"를 한 번 찾아보겠습니다.

BruteForce 알고리즘 관점에서 보면 긴 문자열(H)의 모든 지점에서 찾으려는 문자열(N)을 하나씩 비교해나가보면 됩니다.
이 방법은 H의 모든 지점에 대해서 N개 씩 문자를 비교해야되므로 O( |H| * |N| ) 의 복잡도를 가지게 됩니다.
KMP 알고리즘을 이용하면 복잡도를 **O( |H| + |N| )**으로 획기적으로 줄일 수 있습니다.
KMP 알고리즘을 정리하기 전에 자주 쓰이는 용어부터 정의하고 넘어가겠습니다.
-
접두사 (Prefix)
: 어떤 문자열의 0번 글자(맨 앞)에서부터 시작한 부분 문자열을 접두사라고 합니다.
-
접미사 (Suffix)
: 어떤 문자열의 b번 글자부터 마지막 글자까지로 구성된 부분 문자열을 접미사라고 합니다.
-
부분 일치 테이블 (Partial Match Table)
: 어떤 문자열 N에 대해서, 부분 일치 테이블 pi[ i ] 는 N[ 0 ~ i ] 의 접두사도 되고, 접미사도 되지만 N [ 0 ~ i ] 와 같지는 않은 문자열의 최대 길이 입니다.
ex) "AABAABAC"
접두사 : "A" / "AA" / " AAB" / "AABA" / "AABAA" / "AABAAB" / "AABAABA" / "AABAABAC"
접미사 : "C" / "AC" / "BAC" / "ABAC" / "AABAC" / "BAABAC" / "ABAABAC" / "AABAABAC"
부분 일치 테이블
| pi[0] | "A"의 접두사도 되고 접미사도 되지만 "A"와 같지 않은 문자열의 최대 길이 | 0 |
|---|---|---|
| pi[1] | "AA" 의 접두사도 되고 접미사도 되지만 "AA"와 같지 않은 문자열의 최대 길이 | 1 ("A") |
| pi[2] | "AAB" 의 접두사도 되고 접미사도 되지만 "AAB" 와 같지 않은 문자열의 최대 길이 | 0 |
| pi[3] | "AABA" 의 접두사도 되고 접미사도 되지만 "AABA" 와 같지 않은 문자열의 최대 길이 | 1 ("A") |
| pi[4] | "AABAA" 의 접두사도 되고 접미사도 되지만 "AABAA" 와 같지 않은 문자열의 최대 길이 | 2 ("AA") |
| pi[5] | "AABAAB" 의 접두사도 되고 접미사도 되지만 "AABAAB" 와 같지 않은 문자열의 최대 길이 | 3 ("AAB") |
| pi[6] | "AABAABA" 의 접두사도 되고 접미사도 되지만 "AABAABA" 와 같지 않은 문자열의 최대 길이 | 4 ("AABA") |
| pi[7] | "AABAABAC" 의 접두사도 되고 접미사도 되지만 "AABAABAC" 와 같지 않은 문자열의 최대 길이 | 0 |
KMP 알고리즘은 검색 과정에서 얻는 정보를 버리지 않고 활용해서 더 빠르게 문자열을 검색합니다. 즉, 불일치가 일어났을 때 지금까지 일치한 글자의 수를 이용해서 의미 없는 탐색 과정을 줄여줍니다.
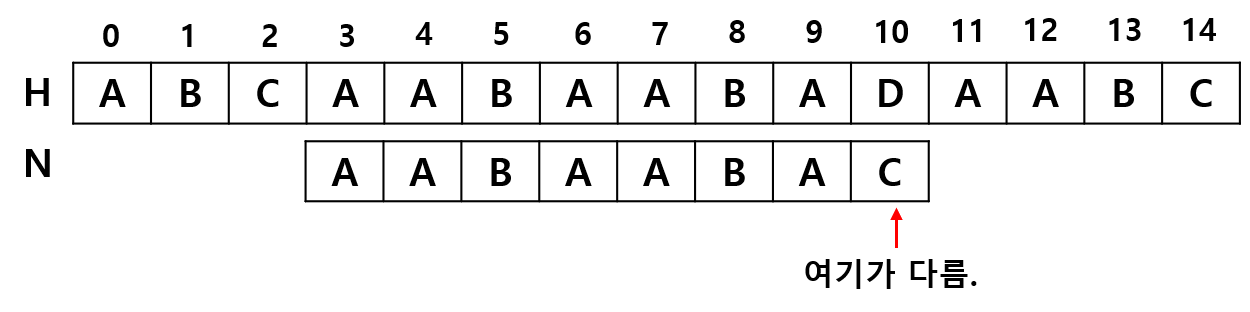
위와 같이 "ABCAABAABADAABC" 에서 "AABAAABAC" 를 찾는 경우를 생각해보겠습니다.
편의를 위해 "ABCAABAABADAABC" 를 문자열H, "AABAAABAC" 를 문자열N 이라고 하겠습니다.
문자열H에서 문자열N을 찾는 과정에서 문자열N의 마지막 부분에서 다르다는 것을 알았습니다. 그럼 우리는 다음과 같이 2가지 작업을 할 수 있습니다.
1) 탐색 시작 지점 점프
현재 탐색을 진행하다 H[10]과 N[7] 에서 불일치가 발생했습니다. 즉, 문자열N에서 일치한 부분은 "AABAABA" 입니다. 일치한 부분의 부분 일치 테이블을 생각해보면 "AABA" 가 접두사와 접미사가 같은 최대 부분 문자열인 것을 알 수 있습니다. 바꿔 생각하면 우리는 접두사 "AABA" 가 접미사 "AABA"로 다시 한 번 등장하고 여기까지는 이미 일치한 부분이므로 접두사 "AABA" 만큼의 탐색을 건너뛰고 접미사 "AABA"부터 탐색을 시작해도 됩니다.
H[3] 에서 탐색을 실패했지만 H[4] 에서 탐색을 시작하는 것이 아니라 H[6] 인 접미사의 시작 부분에서 탐색을 시작해도 됩니다.
2) 실제 탐색 지점 점프
접두사와 접미사가 같은 배열의 길이가 "AABA"로 4입니다. H[6] 부터 탐색을 시작하지만 4글자는 이미 같다는 것을 우리는 알고 있습니다. 따라서, 탐색은 H[6]부터 시작하지만 실제 탐색은 H[10] 과 N[5] 부터 비교를 해보면 됩니다.
이처럼 KMP 알고리즘은 불일치가 일어났을 때 얻을 수 있는 정보들로 의미 없는 탐색 과정을 줄여가며 문자열 검색을 하는 알고리즘입니다.
vector<int> kmp(string H, string N) {
int n = H.size(), m = N.size();
vector<int> ans;
vector<int> pi = getPartialMatch(N);
int begin = 0, matched = 0;
// begin 은 탐색을 시작하는 문자열 H의 위치
// matched 는 현재 탐색을 진행 중에 일치하는 글자의 수
while (begin + m <= n) { // 현재 문자열 H의 탐색 위치부터 문자열 N의 크기를 더했을 때 문자열 H보다 커지면 탐색 종료.
if (matched < m && H[begin + matched] == N[matched]) { // 문자열이 일치할 때
matched++;
if (matched == m) // 끝까지 다 일치했습니다.
ans.push_back(begin);
}
else { // 문자열 불일치 발생
if (matched == 0) begin++; // 일치한 부분이 하나도 없음 -> 시작포인트를 한 칸 앞으로
else {
begin += matched - pi[matched - 1]; // pi 배열을 이용해 다음 시작 지점으로 점프
matched = pi[matched - 1]; // pi 배열을 이용해 이미 일치하는 부분을 건너뛰고 탐색 시작
}
}
}
return ans;
}
vector<int> getPartialMatch(string N) {
int m = N.size();
vector<int> pi(m, 0);
// pi[0] 은 1글자라 정의상 무조건 0이 되므로 1부터 탐색 진행
int begin = 1, matched = 0;
while (begin + matched < m) {
if (N[begin + matched] == N[matched]) {
matched++;
pi[begin + matched - 1] = matched;
}
else {
if (matched == 0) begin++;
else {
begin += matched - pi[matched - 1];
matched = pi[matched - 1];
}
}
}
return pi;
}