Jai Bardhan, Patrik Drozdík, Josef Šivic, Vladimír Petrík
Czech Institute of Informatics, Robotics and Cybernetics (CIIRC), Czech Technical University in Prague

TL;DR: Action-conditioned video-diffusion world models break down in long autoregressive rollouts because they are trained on ground-truth history frames but must condition on their own (imperfect) outputs at deployment — a pathology known as exposure bias. PersistWorld fixes this with an RL post-training scheme that trains the world model directly on its own rollouts, using multi-view visual quality rewards (LPIPS, SSIM, PSNR) to reinforce higher-fidelity predictions. On the DROID benchmark, PersistWorld outperforms the Ctrl-World baseline on all metrics — e.g. LPIPS reduced by 14% on external cameras, SSIM improved by 9.1% on the wrist camera — wins ~98% of 1-to-1 paired comparisons, and achieves an 80% preference rate in a blind human study.
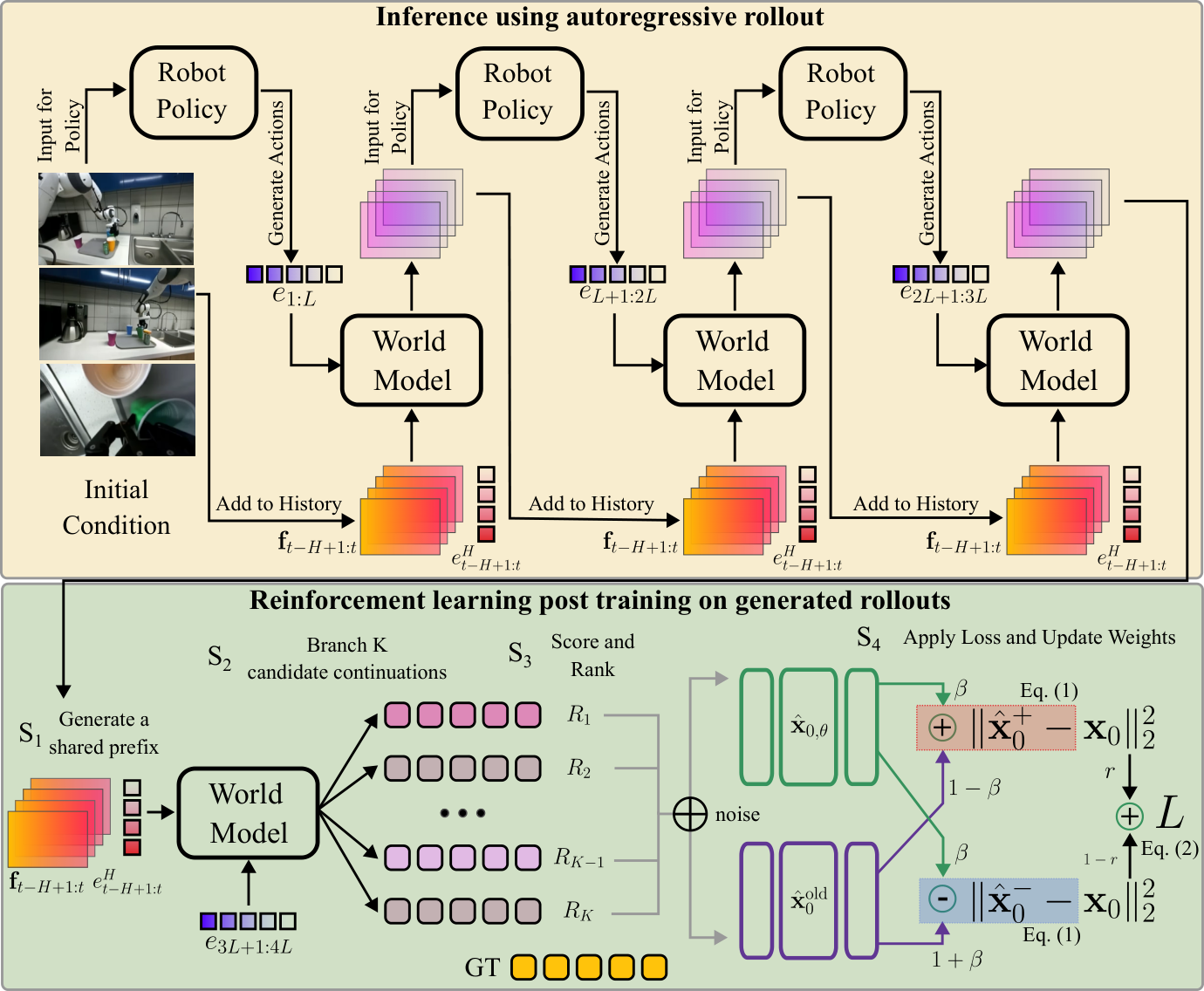
Current robot world models (e.g. Ctrl-World) generate faithful video clips over short horizons. But when deployed autoregressively — each predicted clip fed back as context for the next — errors compound rapidly. Within seconds, manipulated objects lose structural identity, robot end-effectors drift from commanded trajectories, and entire scenes decohere.
PersistWorld adapts DiffusionNFT (a GRPO-style contrastive RL objective for diffusion models) to the autoregressive world model setting. Three key contributions:
-
RL post-training for robot world models. We run the model autoregressively during training and optimize it against its own rollout outputs rather than ground-truth histories. We show the DiffusionNFT convergence guarantees carry over to our setting where the denoising network directly predicts clean frames.
-
A branching training protocol. The model's accumulated history at any rollout step serves as a natural shared context. We generate multiple candidate continuations from the same state, rank them by visual quality, and update the model via group-relative policy optimization. By randomly varying the branch depth, training sees both mild early-stage and severe late-stage error regimes.
-
Multi-view visual rewards. Clip-level rewards combine LPIPS, SSIM, and PSNR across all three camera views (two external + one wrist). Rewards are normalized within each candidate group so the signal reflects relative fidelity rather than absolute values, which vary widely across rollout positions.
| Cameras | Model | SSIM ↑ | PSNR ↑ | LPIPS ↓ |
|---|---|---|---|---|
| External | Ctrl-World† | 0.84 | 23.02 | 0.081 |
| External | PersistWorld | 0.86 | 24.42 | 0.070 |
| Wrist | Ctrl-World† | 0.62 | 17.80 | 0.310 |
| Wrist | PersistWorld | 0.67 | 19.39 | 0.277 |
PersistWorld wins ~98% of 1-to-1 paired comparisons and achieves 80% human preference rate. Gains are concentrated on task-critical foreground regions (manipulated objects and robot arm), not background.
conda create -n persist-world python==3.11
conda activate persist-world
pip install -r requirements.txtTo interact with the π₀.₅ VLA policy, follow the openpi repo instructions separately.
PersistWorld is post-trained on top of Ctrl-World.
| Resource | Description | Size |
|---|---|---|
| clip-vit-base-patch32 | CLIP text/image encoder | ~600 MB |
| stable-video-diffusion-img2vid | Pretrained SVD backbone | ~8 GB |
| Ctrl-World | Base checkpoint (pre-RL post-training) | ~8 GB |
| PersistWorld | PersistWorld checkpoint (post-RL training) | ~8 GB |
| DROID Dataset | Training/validation data | ~370 GB |
Download the PersistWorld checkpoint:
huggingface-cli download jaibrdhn/persistworld checkpoint-5760-merged.pt --local-dir model_ckpt/Starting from an observed state, replay recorded DROID actions through the world model autoregressively:
CUDA_VISIBLE_DEVICES=0 python scripts/rollout_replay_traj.py \
--dataset_root_path dataset_example \
--dataset_meta_info_path dataset_meta_info \
--dataset_names droid_subset \
--svd_model_path ${SVD_PATH} \
--clip_model_path ${CLIP_PATH} \
--ckpt_path ${CKPT_PATH}One interaction step takes ~10s on A100 or ~5s on H100.
Drive the robot in the world model using keyboard commands (l=left, r=right, f=forward, b=backward, u=up, d=down, o=open gripper, c=close gripper):
CUDA_VISIBLE_DEVICES=0 python scripts/rollout_key_board.py \
--dataset_root_path dataset_example \
--dataset_meta_info_path dataset_meta_info \
--dataset_names droid_subset \
--svd_model_path ${SVD_PATH} \
--clip_model_path ${CLIP_PATH} \
--ckpt_path ${CKPT_PATH} \
--task_type keyboard --keyboard lllrrrRun closed-loop rollouts with the π₀.₅ VLA policy inside the world model (requires openpi installation):
CUDA_VISIBLE_DEVICES=0 XLA_PYTHON_CLIENT_MEM_FRACTION=0.4 python scripts/rollout_interact_pi.py \
--task_type pickplace \
--dataset_root_path dataset_example \
--dataset_meta_info_path dataset_meta_info \
--dataset_names droid_subset \
--svd_model_path ${SVD_PATH} \
--clip_model_path ${CLIP_PATH} \
--ckpt_path ${CKPT_PATH} \
--pi_ckpt ${PI_CKPT_PATH}Available task types: pickplace, towel_fold, wipe_table, tissue, close_laptop, stack.
Training runs on 1–2 nodes with 8× A100/H100 GPUs.
Step 1 — Extract SVD-VAE latents (speeds up training significantly):
accelerate launch dataset_example/extract_latent.py \
--droid_hf_path ${DROID_PATH} \
--droid_output_path dataset_example/droid \
--svd_path ${SVD_PATH}Step 2 — Build metadata (JSON manifests + action normalization stats):
python dataset_meta_info/create_meta_info.py \
--droid_output_path ${DROID_OUTPUT_PATH} \
--dataset_name droid# Dry-run on the bundled subset
WANDB_MODE=offline accelerate launch --main_process_port 29501 \
scripts/train_wm.py \
--dataset_root_path dataset_example \
--dataset_meta_info_path dataset_meta_info \
--dataset_names droid_subset
# Full training
accelerate launch --main_process_port 29501 \
scripts/train_wm.py \
--dataset_root_path dataset_example \
--dataset_meta_info_path dataset_meta_info \
--dataset_names droidaccelerate launch scripts/train_nft_wm.py \
--ckpt_path ${BASE_CKPT_PATH} \
--dataset_root_path dataset_example \
--dataset_meta_info_path dataset_meta_info \
--dataset_names droid \
--reward_w_lpips 1.0 \
--reward_w_ssim 1.0 \
--reward_w_psnr 0.03125Key hyperparameters used in the paper: LoRA rank 64, learning rate 1e-4 (Muon optimizer), batch size 64, group size K=16, 6000 steps on 8× H200 GPUs (~3 days). However, Appendix B from the paper shows hyperparameters that can achieve similar performance within 2500 steps (~1 day).
Closed-loop autoregressive evaluation against held-out ground truth:
python scripts/eval_nft_wm.py \
--ckpt_path ${CKPT_PATH} \
--dataset_root_path dataset_example \
--dataset_meta_info_path dataset_meta_info \
--dataset_names droid_subsetPersistWorld is built on Ctrl-World (Guo et al., 2025) which uses Stable Video Diffusion as its backbone. The RL post-training objective is adapted from DiffusionNFT (Zheng et al., 2025). The VLA policy used in interactive rollouts is π₀.₅ from Physical Intelligence.
If you find this work useful, please cite:
@article{bardhan2026persistworld,
title = {PersistWorld: Stabilizing Multi-step Robot World Model Rollouts
via Reinforcement Learning},
author = {Bardhan, Jai and Drozd\'{i}k, Patrik and \v{S}ivic, Josef
and Petr\'{i}k, Vladim\'{i}r},
booktitle = {ArXiv Preprint},
year = {2026}
}This repository was set up with the help of GitHub Copilot and Claude Code.