
한국 청년 정책 2,235건을 수집하고, 5개 LLM으로 답변을 생성한 뒤, 3단계 자동 평가 파이프라인으로 응답 신뢰성을 검증하는 프로젝트입니다.
"Complex policies, solved with a single question."
Policy Pass(정책 패스)는 파편화된 청년 정책 정보를 RAG(검색 증강 생성) 기반으로 사용자 맞춤형으로 제공하고, 응답의 신뢰성을 정량적으로 검증하는 QnA 시스템입니다.
- 공급의 팽창과 인식의 괴리: 청년 정책 예산은 확대되지만, 정작 많은 청년은 정책을 “어디서/어떻게” 찾아야 하는지 모릅니다.
- 정책 조건의 초복잡성: 자격 요건이 까다롭고 문서가 길어, 개인이 공고/행정 문서를 직접 해석하는 비용이 큽니다.
- 정보 탐색의 비효율성: 여러 포털/사이트를 전전하며 필터링해야 해 탐색 시간이 길어집니다.
- 신뢰성 부재: 범용 LLM의 환각(Hallucination)은 오정보로 이어질 수 있어, “근거 기반 답변”과 “검증”이 필수입니다.
- Context-Aware Retrieval: 질문에서 연령/소득/거주지 등 핵심 조건을 반영해 검색 공간을 정밀하게 좁히고 정확도를 높입니다.
- 행정 도메인 특화 Prompt Engineering: 난해한 행정 용어를 사용자의 언어로 풀어주되, 법적 근거의 정확성을 우선합니다.
- Multi-Cloud RAG Architecture: 데이터 수집·인덱싱(오프라인)과 서빙(온라인)을 분리해 파이프라인과 운영을 최적화합니다.
- 신뢰성 평가 파이프라인: RAGAS v0.4, LLM-as-Judge, DeepEval을 결합해 응답을 다면적으로 채점/검증합니다.
RAGAS 기반 핵심 지표로 성능을 제어합니다.
- Faithfulness: 답변이 제공된 문맥에 근거하는지(환각 방지)
- Answer Relevance: 답변이 질문 의도에 부합하는지
- Context Precision: 검색 문서가 질문과 얼마나 밀접한지
- Context Recall: 정답에 필요한 정보가 검색 결과에 포함되는지
- 탐색 시간 단축: 수 시간 걸리던 정책 탐색을 짧은 질의응답으로 대체
- 행정 효율 개선: 반복 문의를 줄이고 정책 전달·안내의 자동화를 촉진
- 사회적 안전망 강화: 정보 격차가 수혜 격차로 이어지지 않도록 근거 기반 안내를 제공
LLM이 생성한 답변을 어떻게 자동으로 검증할 수 있을까?
- RAGAS — 답변이 문서에 근거했는지 정량 측정
- LLM-as-a-Judge — AI가 AI의 답변을 읽고 채점 (G-Eval 방식)
- DeepEval — 문서에 없는 내용을 날조했는지 환각 탐지
단독 평가 최대 30% → 3단계 조합 시 52.0% 결함 탐지 (+22.3%p 향상)
📊 Policy Pass 프로젝트
├── policy-pass-datapipeline-gcp # 데이터 파이프라인 (GCP) — 수집/검색/생성/평가 전체
├── policy-pass-be # FastAPI 백엔드 (LangChain RAG)
├── policy-pass-fe # Streamlit 프론트엔드
├── policy-pass-infra-aws # AWS 인프라 (Terraform)
└── LangChain-RAG-prototype # 초기 프로토타입 (KorQuAD 1.0)
메인 리포지토리. 정책 수집 → FAISS 인덱싱 → Hybrid 검색 → 멀티 LLM 생성 → 3단계 평가까지 전체 파이프라인을 포함합니다.
기술 스택: Python 3.11+ · FastAPI · FAISS · LiteLLM · RAGAS v0.4 · DeepEval · Airflow · GCP Cloud Run
파이프라인 흐름:
정부사이트 → 수집(Airflow) → GCS + MongoDB → FAISS 인덱스
↓
사용자 질문 → Hybrid 검색(Vector+BM25+Rerank) → LLM 생성 → 3단계 평가
FastAPI + LangChain 기반 RAG 백엔드. 정책 검색 및 답변 생성 API를 제공합니다.
Streamlit 기반 프론트엔드. QnA 챗봇, 정책 탐색, 맞춤 추천, 평가 대시보드 4개 페이지로 구성됩니다.
멀티클라우드 인프라 구성. GCP(데이터 파이프라인) + AWS(서빙) 하이브리드 아키텍처입니다.
KorQuAD 1.0 데이터셋 기반 RAG 프로토타입. 본 프로젝트의 초기 실험 버전입니다.
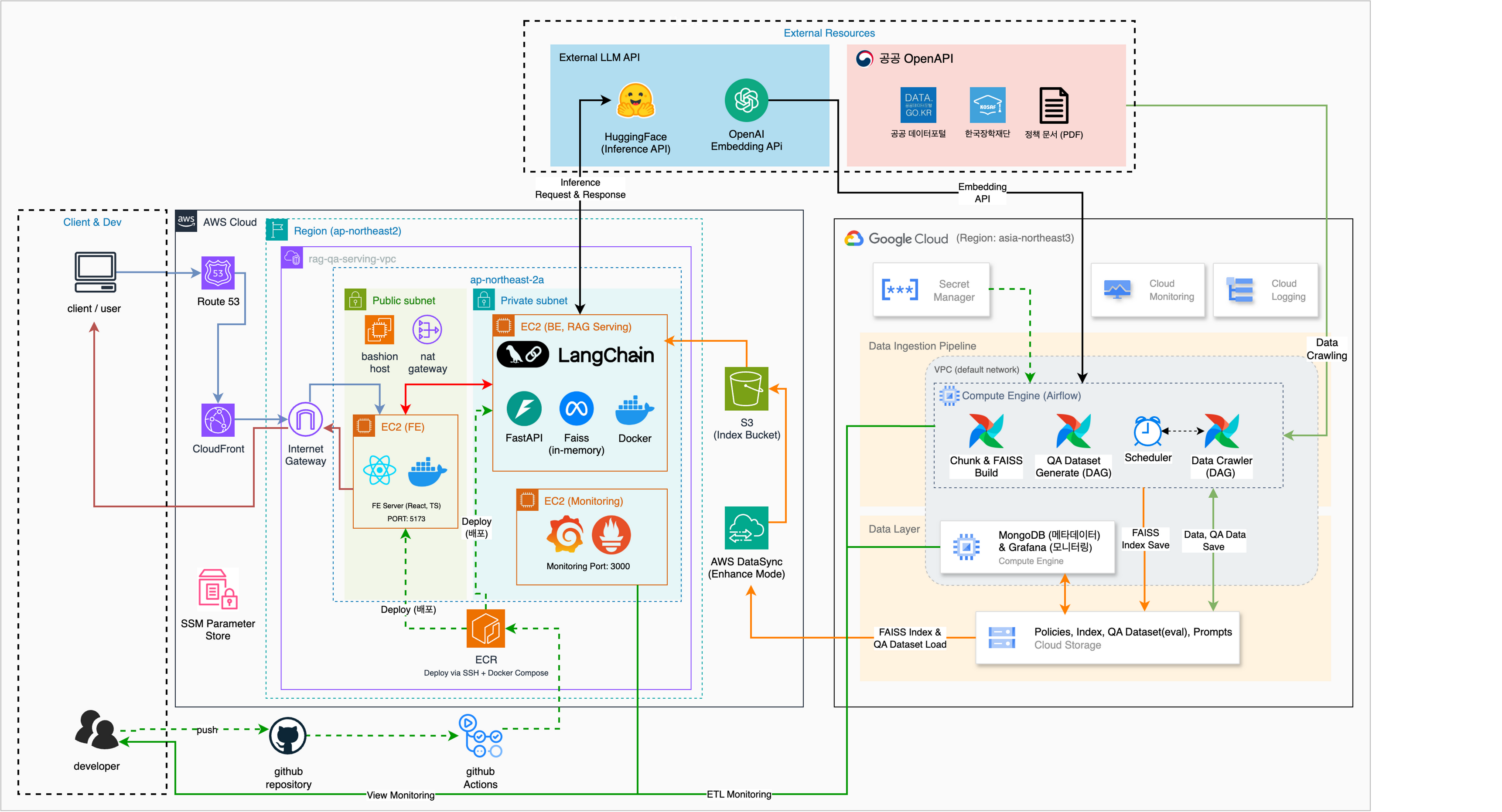
GCP (Offline Pipeline) — 데이터 수집, 청킹, 임베딩, FAISS 인덱스 빌드, Airflow 오케스트레이션
AWS (Online Serving) — FastAPI 백엔드, 프론트엔드, FAISS 검색, LLM 호출, 모니터링
GCP (Offline Pipeline) AWS (Online Serving)
======================== ========================
Data Crawling FastAPI Backend (EC2)
Chunking & Embedding Frontend (EC2)
FAISS Index Build FAISS Index Load & Search
GCS Storage ─────> S3 (via DataSync)
Airflow Orchestration LLM Call & Response
MongoDB (Metadata) Monitoring (Grafana + Prometheus)
| 구분 | 기술 |
|---|---|
| 언어 | Python 3.11+ |
| LLM | LiteLLM (OpenAI · Vertex AI · HuggingFace) |
| 검색 | FAISS + BM25 + Cross-Encoder Rerank |
| 평가 | RAGAS v0.4 · LLM Judge (G-Eval) · DeepEval |
| 백엔드 | FastAPI · Airflow 2.9.3 |
| 프론트엔드 | Streamlit |
| 인프라 | GCP Cloud Run · GCS · MongoDB · Grafana |
| CI/CD | GitHub Actions (5 workflows) |
| 테스트 | pytest (261 tests) |