Use NLP to perform word vectorization, topic modeling and sentiment analysis on movie reviews.
Review Analysis on Rotten Tomatoes
Sophy Huang, Julian Zhao, Zhou Fang
In recent years, watching a movie has always been the top entertainment for people on weekends and holidays. According to the Numbers statistics, US cinemas ticket sales reached 1,235,503,823 (“Movie Market” n.d.) in 2019, which means that a person watched 4 movies in a year on average in the United States. However, as people are busy nowadays and the movie tickets are not that cheap, people tend to turn to movie review websites before they decide on a movie so that they won’t waste time and money on an unsatisfying one. Studies have shown that scores on movie review websites became increasingly tightly linked to movie ticket sales (Wilkinson, 2017). As some moviegoers look up movie reviews before watching a movie, other people also utilize the review websites to share experiences and engage in further discussion after watching a movie. Contemporary recognition of the significance of movie review websites stems mainly from these two trends. In recent years, movie review websites such as Roger Ebert, IMDB, Guardian, and Rotten Tomatoes have gained great attention and popularity.

In our project, we focused on movie reviews on Rotten Tomatoes, which is an American review-aggregation website for film and television (“Rotten Tomatoes” n.d.). Nowadays, it has become one of the most popular movie review websites in the US. Rotten Tomatoes is a website for quick rating (“8 Best” n.d.). People mark their review “fresh” if it’s generally favourable or “rotten” otherwise. Moreover, Rotten Tomatoes has been a trusted movie review source as it uses critics’ data for overall scoring of a film. The website categorizes critics’ and top critics’ reviews. To be specific, to be accepted as a “critic” on Rotten Tomatoes, his or her original reviews must garner a specific number of “likes” from users. Those classified as “top critics” generally write for major newspapers. (“Movie & TV Critics” n.d.) If 60% or more of critics (including top critics) like a movie, the movie earns an overall Fresh score with a red tomato. A movie earns a Rotten score with a green splat if under 60% of critics rate the movie favorably. Since Rotten Tomatoes has been widely used and has clear categories for sentiment and critics, we’re interested in performing review analysis on this website.
In our project, we used different models and methods to analyze movie reviews from the Rotten Tomatoes website. Our research question is mainly composed of two parts:
1) Do top critics’ reviews differ from normal critics’? If so, how do they differ? The original dataset contains three categories of reviewers: amateurs, critics, and top critics. In our project, we focused on the dataset of reviews from critics and top critics. In the modern era of the Internet, it has become significantly easier to submit a body of text and potentially have the entire world see it. However, though this brings a plethora of beautiful possibilities, it has also arguably cheapened the realm of professional publication. Rotten Tomatoes review website selects the critics' review category for people to get more meaningful information with less time. Classifying features of both top critics’ and critics’ reviews could help the Rotten Tomatoes operation team check critics’ performance, consider the necessity of separating top critics from critics, and inspire them an optimized selection of top critics and critics in the future. Moreover, the analysis results may give insights for amateurs reviewers who want to be professional critics, and for critics who want to become top critics.
2) Do “rotten” reviews and “fresh” reviews differ? If so, how do they differ? By classifying movie reviews into positive and negative categories, we could see what the most frequent words people are using to describe a good/bad movie, and what the most frequent reasons are for people to like/dislike a movie. We could summarize features of those compliments and complaints and give suggestions to future movie makers so that they could learn from past movies’ merits and avoid drawbacks when producing future works.
II. Relevant studies From what we’ve discovered, no study has touched on the novel problem of distinguishing between top critics’ comments and non-top critics’ comments. Nevertheless, many studies focus on the binary classification problem of positive and negative comments using sentiment analysis, vectorization, and topic modeling.
https://towardsdatascience.com/sentiment-analysis-with-python-part-1-5ce197074184 In this project, the author implements vectorization on a IMDB movie review dataset and builds a machine learning model for a binary classification problem (positive comment vs. negative comment). The author applies simple regular expression as preprocessing, utilizes a binary CountVectorizer for the transformation, and uses Logistic Regression as the training model. As a result, the model achieves an accuracy of 0.88 for classifying positive and negative comments. The author then looks at the five most distinguished words for both positive and negative comments by sorting the weights of the Logistic Regression. These approaches are similar to our attempts of differentiating subjects of interest by word choice, but what is different in our project is our goal. We aim to use classification methods to see how much we can distinguish two groups, while they aim to build a classification model with high accuracy.
https://towardsdatascience.com/sentiment-analysis-a-how-to-guide-with-movie-reviews- 9ae335e6bcb2 The project called “Sentiment Analysis — A how-to guide with movie reviews” by Shiao-li Green on Towardsdatascience website uses the IMDB movie dataset which has 25,000 labeled reviews for training and 25,000 reviews for testing. The project aims to train a sentiment analysis model and predict the sentiment of testing reviews. After preprocessing data, the author tries several methods—Bag of Words, Word2Vec, and Tf-idf—to transform word representations to numerical versions so that a model can interpret. Then, the author attempts two different models for this dataset: Naïve Bayes and Random Forest. The result shows that Tf-Idf does marginally better, and Naïve Bayes performs slightly better than the Random Forest. The combination of Naïve Bayes and Tf-Idf reaches an accuracy of 0.8478 of sentiment prediction. This project looks at sentiments of movie reviews in a different direction than ours but provides us with insights into how different methods aid in analyzing sentiments. Our project steps into the conversation by performing sentiment analysis to distinguish attitudes from groups of top critic vs. critic reviews and fresh vs. rotten reviews.
III. Data The dataset for our project is provided through the Kaggle platform by user Stefano Leone, who scraped the movie reviews from the publicly available website Rotten Tomatoes (https://www.rottentomatoes.com). The data has been directly scraped from the website, but the technique is not disclosed by Stefano Leone. The data is collected and updated as of 2020-10-31. Rotten Tomatoes was launched on August 12, 1998. So the data we use in our project would be a collection of movie reviews from 1998 to 2020.
Instances in the dataset include rotten_tomatoes_link (i.e., link from which the review data was scraped), critic_name (i.e., name of users who rated the movie), top_critic (i.e., a boolean value of whether the critic is a top critic or not), publisher_name (i.e., name of the publisher for which the critic works), review_type (i.e., fresh or rotten), review_score, review_date, and review_content. There are a total of 17,712 instances, and each instance consists of raw data (directly scraped from the website). One side note is that every movie review page consists of 2 review sections—critic reviews and audience reviews. However, because many movies do not have featured audience reviews but most movies have critic reviews, and critic reviews come from professionals, we will only be focusing on critic reviews for this project, which corresponds to this dataset. For the review_type variable, it is labeled according to the Tomatometer score provided by critics: it shows as “rotten” when at least 60% of reviews are positive and “rotten” when at least 60% of reviews are negative. We will only be using top_critic, review_type, and review_content in this project.
IV. Methods We did all of our analysis with Python. We wrote and shared our code via Jupyter Notebook. We explored differences between fresh and rotten reviews, critics and top critics reviews mainly from the following three dimensions (with specific tools in parentheses):
- Word Choice (CountVectorizer + Logistic Regression)
- Topics/Focuses (Topic Modelling)
- Sentiments (Sentiment Analysis)
Here we’ll show the methods we used for analyzing critics’ and top critics’ reviews as a demonstration of our approaches. Same methods were applied to fresh and rotten reviews.
Preprocessing First, we preprocessed our dataset by performing text normalization. We did this by
- Getting rid of null content (NA’s)
- Turning all text into lowercase
- Tokenizing text (split text into a list of words)
- Removing stopwords (a set of very common words like the, a, and, etc.)
- Removing special characters (so that our word lists only contains letters a-z and numbers 0-9)
We added a column called “processed_review” to store processed textual data so that our data was ready for analysis.

Then we selected only the “processed_review” column and the column indicating our groups of interest (in this case, top_critic). We also performed subsetting to further separate the selected dataset (rt_critic) into two datasets: one contained only reviews written by top critics (rt_top), and the other contained only those written by critics (rt_nottop). These datasets were helpful in later approaches of topic modeling and sentiment analysis.
1) Word Choices (CountVectorizer + Logistic Regression) We used both classification and frequent word to explore word choice differences between different categories (top critic vs. critic reviews, fresh vs. rotten reviews). We randomly selected 50,000 reviews (25,000 each) from the original dataset to balance our dataset used for classification and converted reviews written by top critics to 1’s and those written by critics to 0’s.
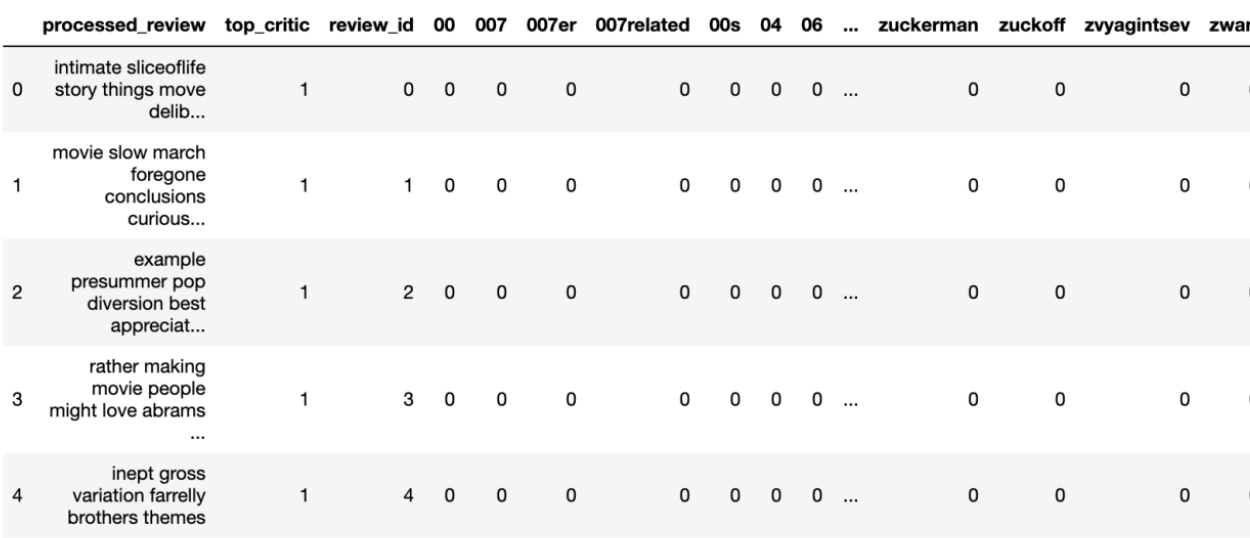
Classification After tokenization, we vectorized the text by setting up CountVectorizer from sklearn’s library and fitting it on our dataset to transform the text into a frequency count in the form of vectors. To be specific, we looked at all the unique words in our dataset and then counted how many times these words appeared in each of the pieces of texts, resulting in a vector representation of each piece of text.
This process gave us a table (review-term matrix) with each unique word as a separate column and each review as a separate row with its index.
Then, we ran the classifier. We used train_test_split (function from the sklearn package) to divide our dataset into training set and testing set. Since our focus is to determine if it is plausible to differentiate comments using countVectorizer (instead of building the best model to classify them), there is no need to build a complicated system to estimate the exact accuracy of our model. In comparison, implementing train_test_split to evaluate our accuracy is time efficient. After splitting the training and testing dataset, we used a logistic regression model to classify critics’ reviews and top critics’ reviews.

We also calculated featured weights for 5 words that had the highest coefficients (i.e., words that most likely indicated 1’s, in this case, top critics) and 5 words that had the lowest coefficients (i.e., words that most likely indicated 0’s, in this case, critics).
Most Frequent Words When calculating most frequent words, we looked at the subsets. For example, we counted the Top 20 Most Frequent words in top critics’ reviews by first creating a new dataframe with all the terms and their frequencies. Since the dataframe was ordered with ascending frequency, the tail 20 words were the Top 20 most frequent words. We analyzed them in forms of graphs and tables, and we will present the visualizations in the analysis/discussion section.
2) Topics/Focuses (topic modeling) In order to perform topic analysis, we used Little MALLET Wrapper in Python. MALLET (originally written in Java) is a software package for topic modeling and other natural language processing techniques. We created a sub folder and changed directories to store out outputs. We set the number of topics to 5. Then we imported the data and used the little mallet wrapper to train the topic model for top critics’ reviews and critics’ reviews. Then we printed the 5 topics with 20 keywords each. Detailed explanations of outputs will be given in the Analysis/Discussion section.
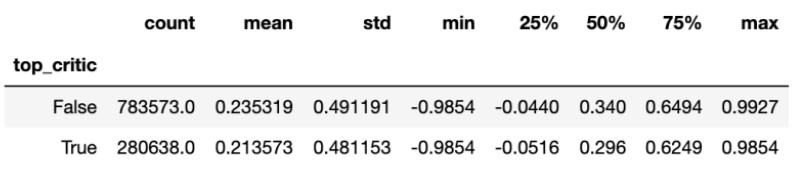
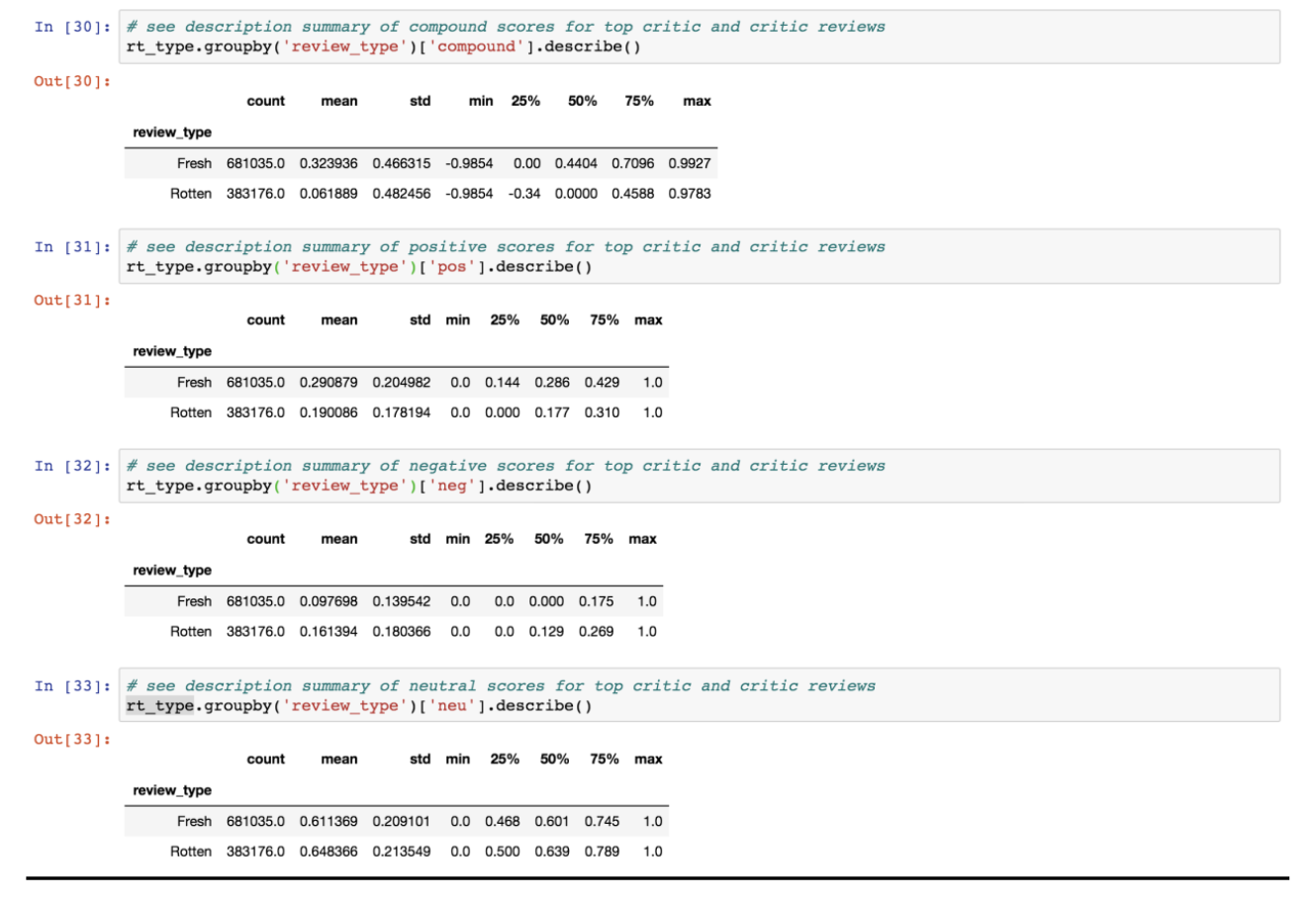
3) Sentiments (Sentiment Analysis) The last part of our methods was to analyze sentiments. We performed sentiment analysis (vader’s SentimentIntensityAnalyzer) on processed review text within the top critic/critic dataset, and then put positive, negative, neutral and compound scores of each review into the dataframe. The compound score refers to the overall sentiment score of a review (1 means most extreme positive, -1 means most extreme negative). In the three subcategories of sentiment (positive, negative, and neutral), the score ranges from 0-1.

Then we grouped the results by top critic (top_critic==True) and critic (top_critic==False) and printed their corresponding summaries of compound/negative/neutral/positive score. The example below is a summary of the compound score for reviews written by top critics and critics, which includes useful statistics such as number of records (count), average score (mean), standard deviation (std), minimum and maximum (min/max).
Another method we implemented was independent samples t-test using ttest_ind from scipy stats, which compared the means of scores for two groups (in this case, top critics and critics). This function returns statistic, or t-statistic, and p-value.
V. Results/Analysis
In the analysis of fresh vs. rotten reviews, we use “critic” to refer to both top critics and critics because the type of critics is no longer the main focus.
1) Word Choice
Classification
Results from our classification model showed that the accuracy was 0.7488. That is, the model could successfully predict whether a review is positive or negative with 74.88% accuracy rate. We can say that it’s significantly different from random guesses and conclude that this model is effective in classifying fresh reviews from rotten reviews to certain extent. This result also implies that the word choices from fresh and rotten reviews are different. The following sections will further explore their differences.

The list of words with feature weights (as shown above) shows five words that most strongly indicate a fresh review (words with positive scores) or a rotten review (words with negative scores). The weighted words in rotten reviews are straightforward in interpretation. When reviewers describe a movie as “unfunny”, “illconceived”, “uninspired”, “halfbaked” or “dud”, they are very likely to give a rotten tomato to the movie. Similarly, when a critic describes a movie as “priceless”, he or she will very likely give a fresh tomato to the movie. However, the other four words, which are specific nouns or adjectives, are rather abstract for interpretation. Maybe when a critic becomes detailed enough to describe specific objects in a movie, it indicates that he or she is very likely to have watched the movie very carefully so that they tend to give a fresh tomato. From this finding, we can see that the negative weighted words are relatively straightforward, and the positive words require more context for interpretation. Therefore, an accuracy of 0.75 is suitable given these coefficients. In the future, the weighted feature should be combined with frequencies of words for more accurate interpretation.
Word Frequency
We printed the top 20 most frequent words in both fresh and rotten reviews as presented below.
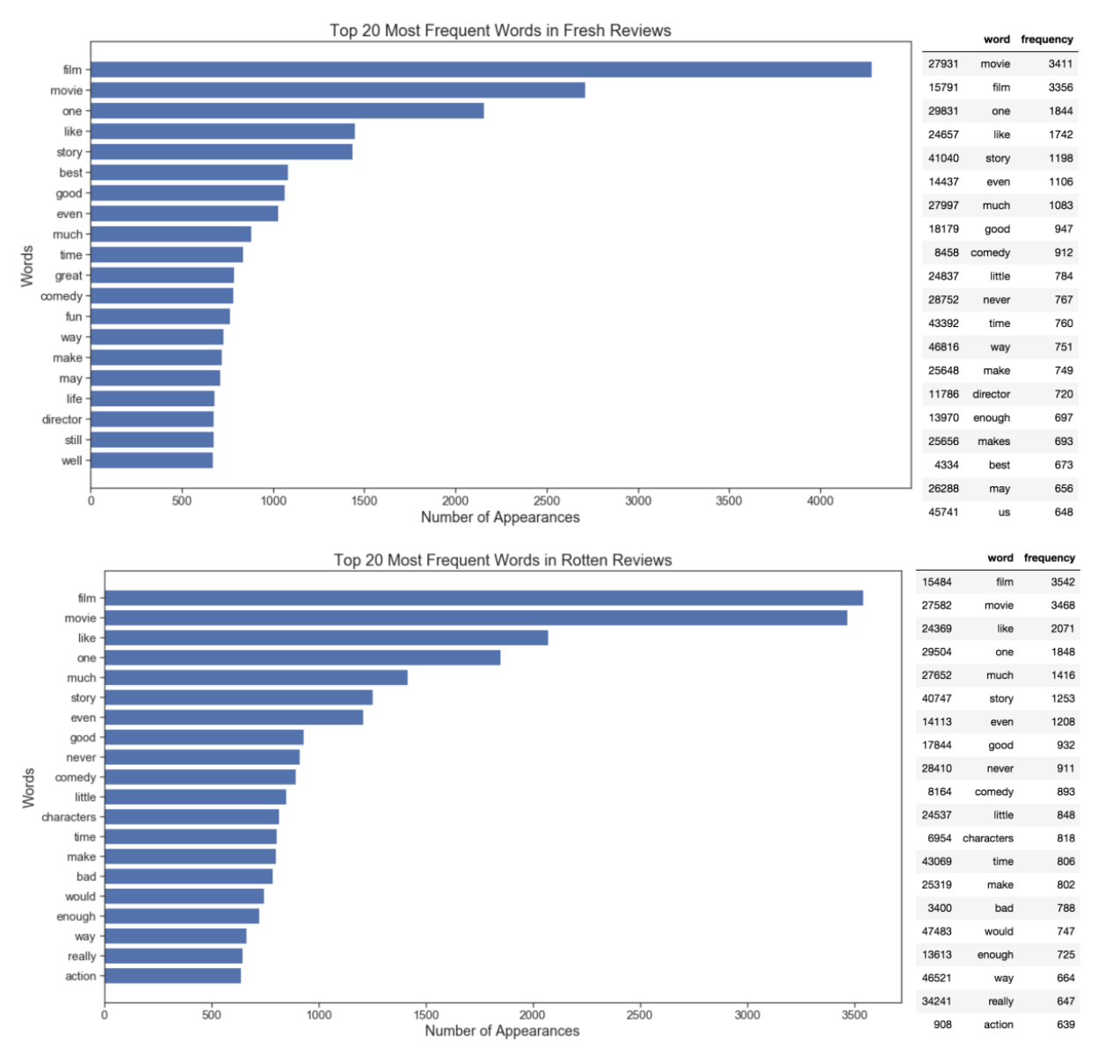
We can see that their words distributions are roughly similar, and they are also similar to top words from top critic/critic reviews. This means that overall, words like “film”, “movie”, “like”, “one”, “much” are frequently used in reviews. Maybe in the future, these words could also be counted as stopwords for more effective analysis. Below are some interesting finds regarding the most frequent words from fresh vs. rotten reviews:
● For the word “like”, its frequency in fresh reviews is around 1,500 while its frequency in rotten reviews is more than 2,000. Maybe people are more likely to use other positive words to describe a satisfactory movie in fresh reviews and more likely to use “don’t like” to describe an unsatisfactory one in rotten reviews, which causes “like” to be more frequent in rotten reviews. Another interpretation is that rotten reviews may use more “like” as a preposition or modal particle instead of using “like” as a word representing their preferences.
● “Best”, “great” and “fun” appear as the 6th, 11th and 13th most frequent words in fresh reviews, but they don’t appear in the top 20 words of rotten reviews. Similarly, “bad”, “never” appear in rotten reviews top words, but don’t appear in the fresh ones. These are understandable because fresh reviews tend to be more positive, while rotten reviews tend to be more negative.
● “Characters” ranks 12th in rotten reviews but doesn’t appear in the fresh list. “Director” ranks 18th in fresh reviews but doesn’t appear in the rotten list. This indicates that when critics think a movie is satisfactory, he or she will be more likely to pay attention to the director. However, when a critic thinks a movie is unsatisfactory, he or she will focus on the characters more.
● Rotten reviews contain the word “much” about 50% more than fresh reviews, indicating that rotten reviews may have more emphasis on degrees of attitudes.
● “Comedy” appears about 800 times in fresh reviews but about 900 times in rotten reviews. This indicates that critics are mostly neutral, but slightly unsatisfactory with comedy movies.
Since the classification model can be concluded as effective, we can say that the findings in the frequent words are significant. For the top 20 most frequent words, we can see that there are many differences between fresh reviews and rotten reviews. However, since the classification model’s accuracy is 0.7488, we should still be cautious when applying these findings to broader contexts. In the future, the findings should be combined with more qualitative research on films and film reviews to derive more comprehensive conclusions about differences among fresh and rotten reviews.
2) Topics/Themes (Topic Modeling)


From the results of topic modeling, we see that the differences between fresh vs. rotten reviews are more observable than those between top critics’ and critics’ reviews. The topics are still rather vague, so we didn’t label each topic. Below are several findings:
● Both Topic 3 in fresh reviews and Topic 1 from rotten reviews contain words “comedy”, “fun” and “romantic”. However, in the topic, fresh reviews contain more positive adjectives like “entertaining”, “fun”, “humor”, “thriller”, “enjoyable”, “romantic” and “smart”. Rotten reviews contain more genre vocabularies like “hollywood”, “horror”, “humor”.
● Fresh reviews contain a rather humanitarian topic (Topic 2), which contains elements like “love”, “world”, “family”, “war”, “man”, “human”, “tale”. Although Topic 4 from rotten reviews also deals with topics like “love”, “work” and “material”, the specific humanitarian elements are not so much as in fresh reviews. From this we can interpret that when critics are satisfied about a movie, they’re more likely to pay attention to those humanitarian details.
● Both Topic 0 from fresh reviews and Topic 2 from rotten reviews deal with technical things. The technical components of a movie affects critics’ satisfaction about a movie.
Also, results from the topic modeling should be combined with more qualitative research to draw more conclusive findings about fresh and rotten reviews.
3) Attitudes (Sentiment Analysis)
Sentiment Score Distributions
Boxplots of Sentiment Scores
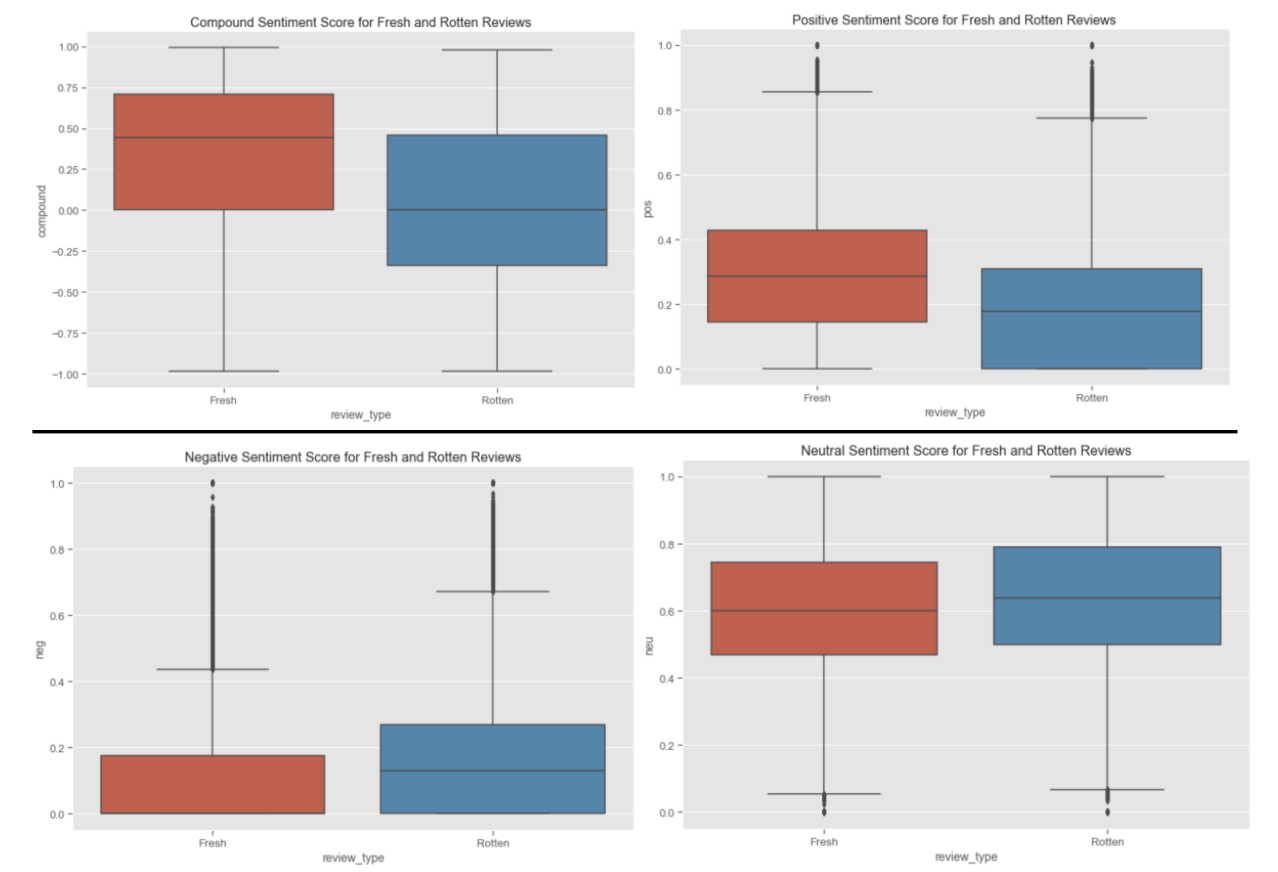
From the summary of sentiment scores and the visualized box plots, we can see that the sentiments for fresh and rotten reviews are different. Our findings are shown below:
● The mean of compound scores of fresh reviews is around 0.45 while that of rotten reviews is around 0.0. It is understandable that fresh reviews bear more positive sentiments than rotten reviews. However, the compound score of rotten reviews is mostly neutral, but slightly positive according to the boxplot distribution. It is counterintuitive since we expect the rotten reviews should have a negative compound score in sentiment.
● Neutral sentiment has the highest mean scores among all types of scores in both fresh and rotten reviews.
● Fresh reviews bear more positive sentiments, rotten reviews bear more negative sentiments.
T-test
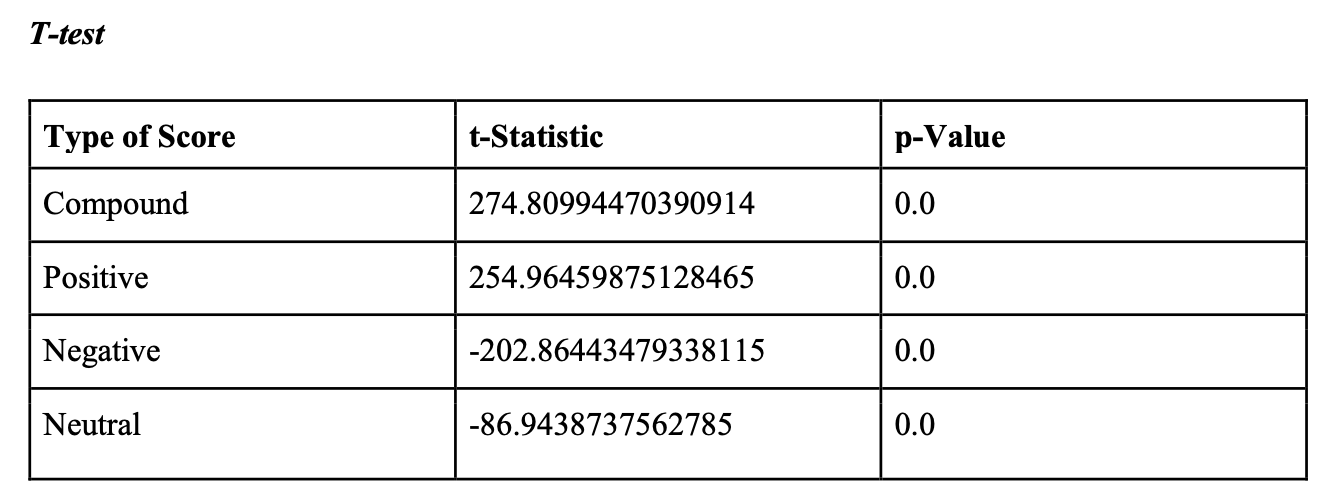
We conducted t-tests to find whether the sentiment scores are significantly different for fresh and rotten reviews. The results show that all 4 t-statistics are very large in absolute values and the corresponding p-values are very small. It indicates that sentiments of fresh reviews are very different from rotten reviews.
Results from sentiment analysis are consistent with our findings from word choices and topics for fresh vs. rotten reviews, which demonstrates that top critics’ reviews are significantly different from critics’ reviews. Therefore, we could conclude that the wording of fresh reviews is different from that of rotten reviews.
VI.Crosstab Analysis
The following three charts are crosstab analysis combining critic/top critic with fresh/rotten categories.
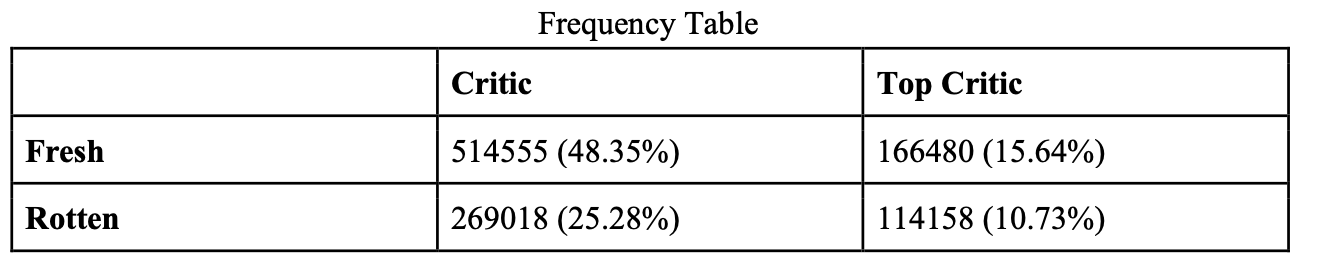
From the frequency table, we can see that the number of critics is about three times that of top critics. Moreover, for critics, the proportion of fresh to rotten reviews is about 1.91 while for top critics, the proportion is around 1.46. The results indicate that both critics and top critics write fresh reviews. However, top critics are more likely to throw rotten tomatoes, indicating they’re more critical of films.

From the table showing average word counts, we can see that the mean of movie review length is about 21 words. Fresh reviews are slightly longer than rotten reviews. Top critics tend to write slightly longer reviews than critics.
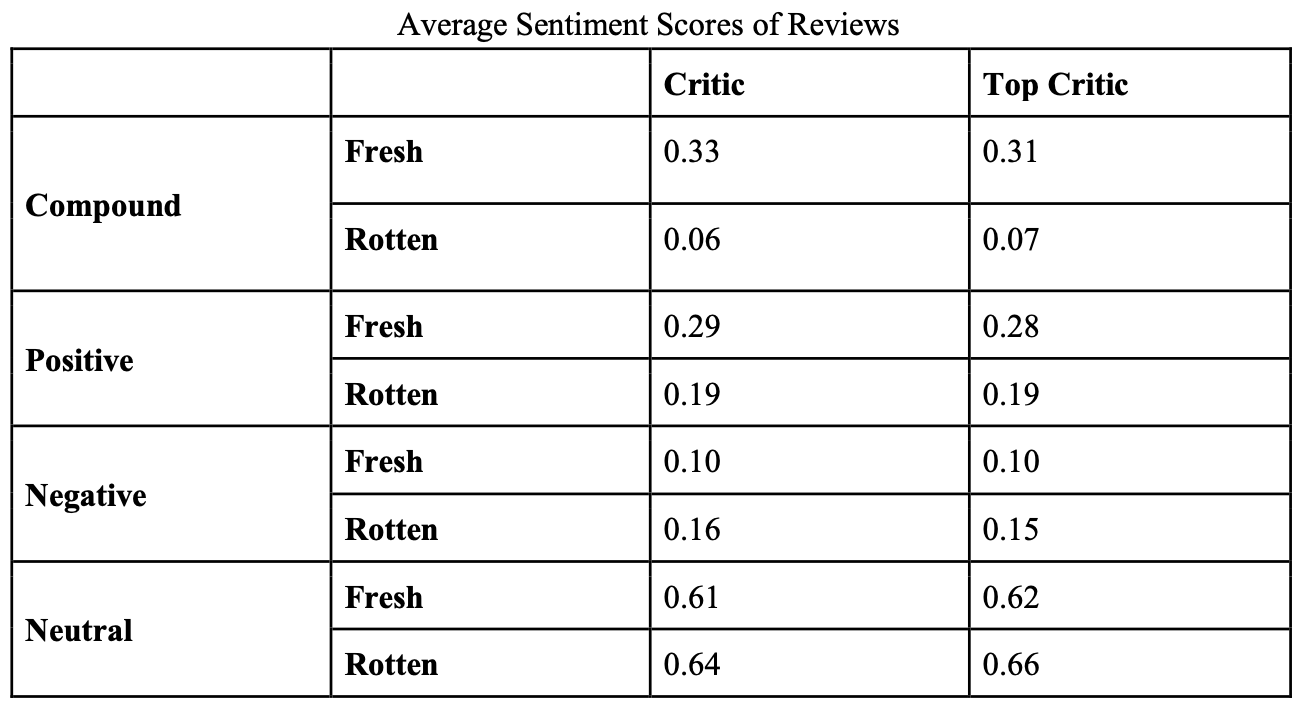
From the table showing average sentiment scores, we can see that differences are not significant when we compare numbers horizontally between reviews written by critics and top critics. For example, compound scores are 0.33 and 0.31 for fresh reviews from critics and top critics respectively; and compound scores are 0.06 and 0.07 for rotten reviews from critics and top critics respectively. However, differences are bigger if we compare numbers vertically between fresh and rotten reviews. For example, compound scores are 0.33 and 0.06 for fresh and rotten reviews by critics respectively; and compound scores are 0.31 and 0.07 for fresh and rotten reviews by top critics respectively. These findings are consistent with our previous sections such that differences are more apparent in fresh and rotten reviews than in top critics’ and critics’ reviews.
VI. Conclusion
Based on our methods and results, we have some answers to our research questions and conclude our findings below. However, there are still limitations of our models and potential space for further improvement.
We conclude that “rotten” reviews differ significantly from “fresh” reviews. Firstly, from the perspective of word choice, the classification model predicts a rotten or a fresh review with an accuracy of 0.7488, indicating that the differences between rotten and fresh reviews are significant enough to classify features. From the top 5 words with feature weights, we see and interpret that fresh reviews correlate more with specific nouns while rotten reviews correlate more strongly with negative adjectives. Secondly, from the top 20 most frequent words list, we find several discernable differences between fresh and rotten reviews (details in the result section). Thirdly, the 5 topics derived from each category have some obvious differences besides several similarities. Lastly, from both t-tests and boxplots, we find that fresh reviews are significantly more positive in sentiments than rotten reviews.
The results can be used as suggestions for future film makes, investment groups and marketing companies. For example, in the topic modeling, we find that fresh reviews bear more humanitarian elements than rotten ones. So in the future, when an investment group is deciding on whether to give funds to a movie, it can see whether the film contains such elements. In the feature weights result, we found that the words “unfunny”, “illconceived”, “uninspired” and “halfbaked” correlated most strongly with rotten reviews. When a marketing company decides whether to market a film, it can refer to the movie preview comments. If those words appear in the comments, the movie is likely to be an unsatisfying one. Also, it’s easy to mistakenly rate a satisfying movie as “rotten” or throw a fresh tomato to an unsatisfying movie. As the result demonstrates strong differences in sentiment for rotten and fresh reviews, Rotten Tomatoes could use sentiment analysis to help correct wrong ratings.
Our findings regarding differences between rotten and fresh reviews also bear limitations. For example, we only look at five words with the most significant feature weights. Maybe the top 5 words can’t represent the big picture. For further improvement, we would also find out the frequencies and specific uses of those words to make sure that they are not mere coincidences. Other limitations are similar with those explained for the first question.
References
Movie Market Summary 1995 to 2020. (n.d.). Retrieved from https://www.the- numbers.com/market/ Movie & TV Critics. (n.d.). Retrieved from https://www.rottentomatoes.com/critics Rotten Tomatoes. (n.d.). In Wikipedia. Retrieved December 3, 2020, from https://en.wikipedia.org/wiki/Rotten_Tomatoes Wilkinson, A. (2017). Rotten Tomatoes, explained. Retrieved December 05, 2020, from https://www.vox.com/culture/2017/8/31/16107948/rotten-tomatoes-score-get-their-ratings-top- critics-certified-fresh-aggregate-mean 8 Best Movie Review Websites and Podcasts. (n.d.). Retrieved from https://evergreenpodcasts.com/blog/8-best-movie-review-websites-and-podcasts