![]()
Embed. Search. Rerank. — The Complete Text Search Engine in a Single Library.
DeepTextSearch is a production-ready Python library for multilingual text search, recommendation, and reranking. It combines transformer-based semantic embeddings, FAISS/ChromaDB/Qdrant/PostgreSQL/MongoDB vector stores, BM25 keyword search, and cross-encoder reranking into a clean, simple API — ready for RAG pipelines, agentic AI, and production deployments.
- Hybrid Search — dense semantic search + BM25 keyword search with Reciprocal Rank Fusion
- Pluggable Vector Stores — FAISS (default), ChromaDB, Qdrant, PostgreSQL (pgvector), MongoDB Atlas
- Cross-Encoder Reranking — tiny to large reranker models, from ~17 MB to 2.2 GB
- Any HuggingFace Model — use any sentence-transformers embedding or cross-encoder model, or your own fine-tuned model
- Multilingual — 100+ languages with BGE-M3 (default model)
- GPU & CPU — auto-detects CUDA/MPS/CPU, or set explicitly
- MCP Server — built-in Model Context Protocol server for Claude Desktop, Claude Code, Cursor
- LangChain Integration — drop-in retriever for LangChain RAG chains
- LlamaIndex Integration — drop-in retriever for LlamaIndex query engines
- Agent Tool Interface — callable tool for OpenAI/Claude function calling
- Incremental Indexing — add/delete documents without re-embedding
- Metadata Filtering — store and filter by document metadata
- Persistent Storage — save/load indexes to any local path
Hybrid search (dense + BM25) consistently outperforms either method alone — +17% Hit@1 over BM25 on SciFact:
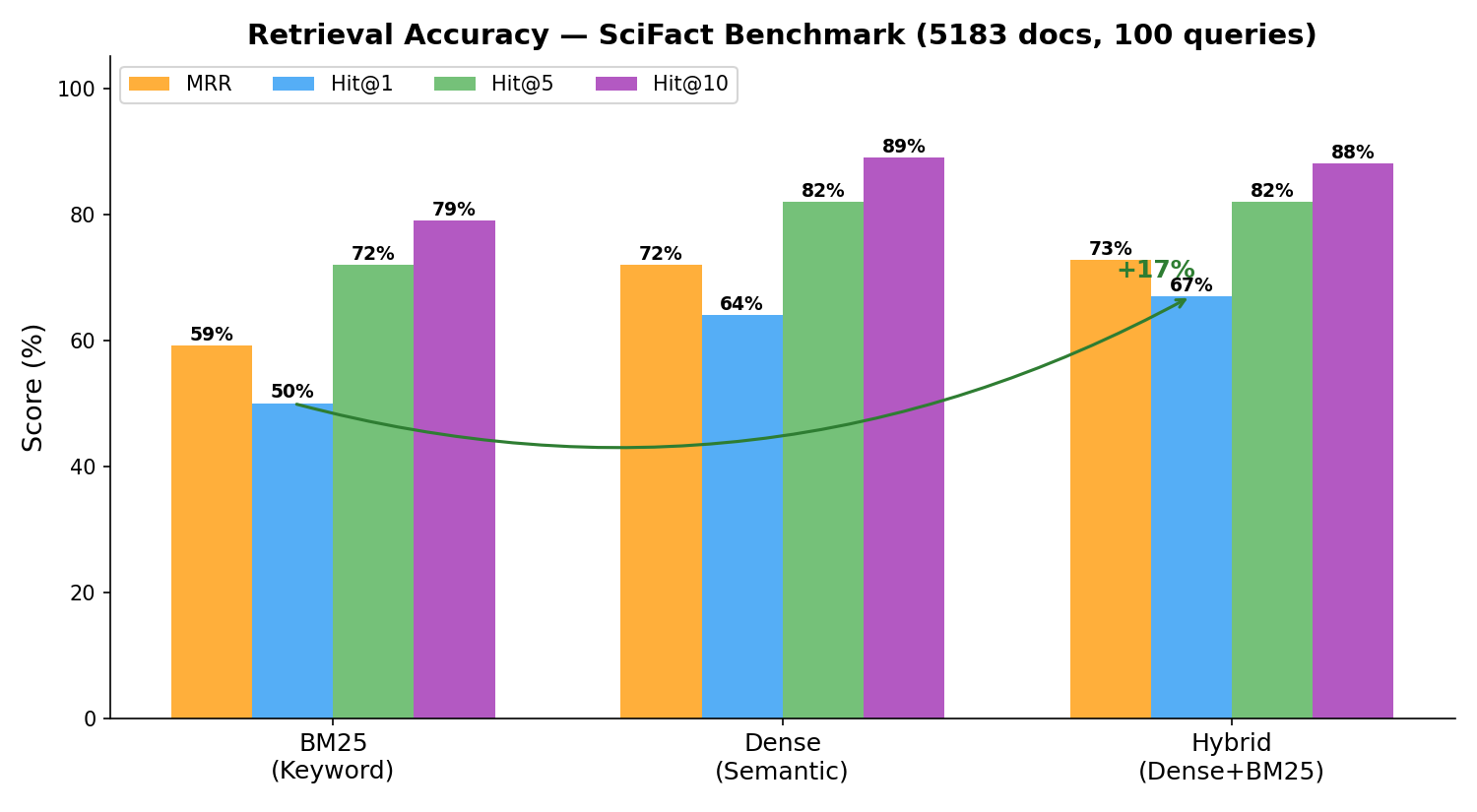
Choose the right speed/accuracy trade-off — from 17 MB edge models to high-accuracy production models:
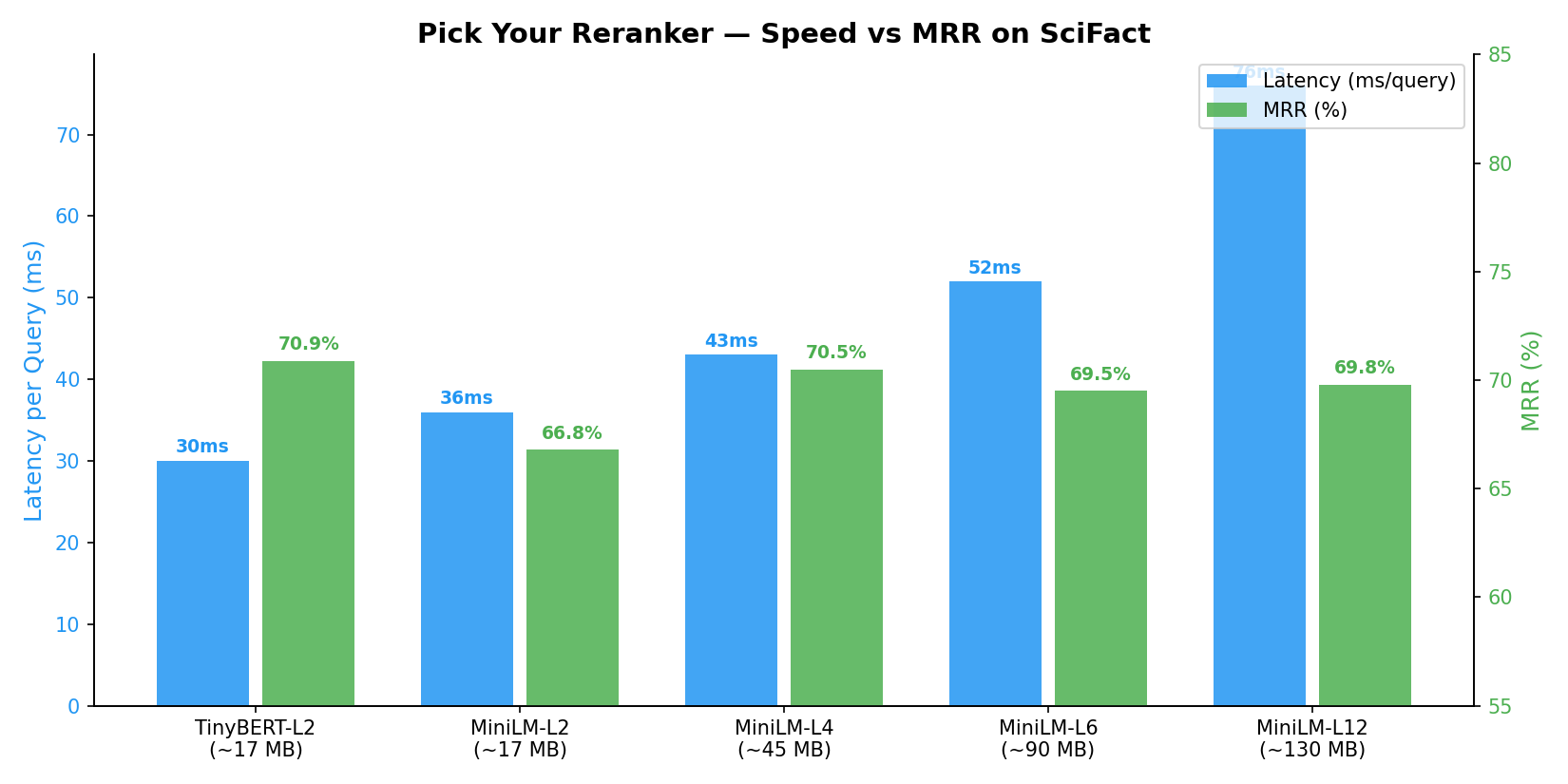
Benchmarked on SciFact (BEIR benchmark, 5183 docs, 100 queries) with BAAI/bge-small-en-v1.5 embeddings on NVIDIA RTX A6000.
From PyPI:
pip install DeepTextSearchFrom GitHub (latest):
pip install git+https://github.com/TechyNilesh/DeepTextSearch.gitOptional extras:
| Extra | Command | What it adds |
|---|---|---|
| ChromaDB | pip install 'DeepTextSearch[chroma]' |
ChromaDB vector store backend |
| Qdrant | pip install 'DeepTextSearch[qdrant]' |
Qdrant vector store backend |
| PostgreSQL | pip install 'DeepTextSearch[postgres]' |
PostgreSQL + pgvector backend |
| MongoDB | pip install 'DeepTextSearch[mongo]' |
MongoDB Atlas Vector Search backend |
| MCP Server | pip install 'DeepTextSearch[mcp]' |
MCP server for agentic AI |
| LangChain | pip install 'DeepTextSearch[langchain]' |
LangChain retriever integration |
| LlamaIndex | pip install 'DeepTextSearch[llamaindex]' |
LlamaIndex retriever integration |
| GPU | pip install 'DeepTextSearch[gpu]' |
FAISS GPU acceleration |
| Everything | pip install 'DeepTextSearch[all]' |
All optional dependencies |
from DeepTextSearch import TextEmbedder, TextSearch
# 1. Embed your corpus
embedder = TextEmbedder()
embedder.index([
"Python is a versatile programming language.",
"Machine learning is transforming industries.",
"FAISS enables fast similarity search.",
"Natural language processing understands text.",
])
# 2. Search
search = TextSearch(embedder)
results = search.search("What is NLP?", top_n=3)
for r in results:
print(f"[{r.score:.4f}] {r.text}")DeepTextSearch supports multiple vector store backends. FAISS is the default (zero config), but you can swap to any database:
| Backend | Install | Best For |
|---|---|---|
| FAISS (default) | Included | Local/embedded, fast prototyping, maximum speed |
| ChromaDB | pip install 'DeepTextSearch[chroma]' |
Simple persistent storage, small-medium projects |
| Qdrant | pip install 'DeepTextSearch[qdrant]' |
Production with metadata filtering, self-hosted |
| PostgreSQL | pip install 'DeepTextSearch[postgres]' |
Enterprise, existing Postgres infrastructure |
| MongoDB | pip install 'DeepTextSearch[mongo]' |
MongoDB Atlas, document-oriented workflows |
| Custom | — | Pass any BaseVectorStore subclass |
# FAISS (default) — local, fast, no setup
embedder = TextEmbedder()
# FAISS with HNSW index for faster approximate search
embedder = TextEmbedder(vector_store="faiss", index_type="hnsw")
# FAISS with IVF index for large-scale search
embedder = TextEmbedder(vector_store="faiss", index_type="ivf")
# ChromaDB — persistent local storage
embedder = TextEmbedder(vector_store="chroma", index_dir="./my_chroma_db")
# Qdrant — local persistent or remote server
embedder = TextEmbedder(vector_store="qdrant", index_dir="./my_qdrant_db")
# PostgreSQL — with connection string, table name, and metadata schema
embedder = TextEmbedder(
vector_store="postgres",
store_config={
"connection_string": "postgresql://user:pass@localhost/mydb",
"table_name": "article_vectors",
"metadata_schema": {
"category": "TEXT",
"language": "TEXT",
"year": "INTEGER",
},
},
)
# MongoDB — with database, collection, and metadata fields
embedder = TextEmbedder(
vector_store="mongo",
store_config={
"connection_string": "mongodb+srv://user:pass@cluster.mongodb.net",
"database_name": "search_db",
"collection_name": "articles",
"index_name": "article_vector_index",
"metadata_fields": ["category", "language", "author"],
},
)
# Custom vector store
from DeepTextSearch import BaseVectorStore
class MyStore(BaseVectorStore):
# implement add, search, delete, count, save, load
...
embedder = TextEmbedder(vector_store=MyStore())Any sentence-transformers compatible model from HuggingFace works:
| Model | Dimensions | Size | Languages | Description |
|---|---|---|---|---|
BAAI/bge-m3 |
1024 | ~2.2 GB | 100+ | Default. Best multilingual, dense+sparse |
sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 |
384 | ~470 MB | 50+ | Fast multilingual |
intfloat/multilingual-e5-large |
1024 | ~2.2 GB | 100+ | Strong multilingual |
BAAI/bge-small-en-v1.5 |
384 | ~130 MB | English | Tiny & fast, great for prototyping |
BAAI/bge-base-en-v1.5 |
768 | ~440 MB | English | Balanced quality/speed |
BAAI/bge-large-en-v1.5 |
1024 | ~1.3 GB | English | Highest quality English |
sentence-transformers/all-MiniLM-L6-v2 |
384 | ~90 MB | English | Ultra lightweight |
thenlper/gte-small |
384 | ~67 MB | English | Tiny but powerful |
nomic-ai/nomic-embed-text-v1.5 |
768 | ~548 MB | English | Long context (8K tokens) |
# Use any model — just pass the HuggingFace name
embedder = TextEmbedder("BAAI/bge-small-en-v1.5")
embedder = TextEmbedder("intfloat/e5-large-v2")
embedder = TextEmbedder("Alibaba-NLP/gte-Qwen2-1.5B-instruct")
# Use a local fine-tuned model
embedder = TextEmbedder("./my-fine-tuned-model")Any cross-encoder model from HuggingFace works:
| Model | Size | Languages | Description |
|---|---|---|---|
cross-encoder/ms-marco-TinyBERT-L-2-v2 |
~17 MB | English | Smallest reranker. Ultra fast, CPU-friendly |
cross-encoder/ms-marco-MiniLM-L-2-v2 |
~17 MB | English | Tiny 2-layer. Minimal latency |
cross-encoder/ms-marco-MiniLM-L-4-v2 |
~45 MB | English | Small 4-layer. Resource-constrained environments |
cross-encoder/ms-marco-MiniLM-L-6-v2 |
~90 MB | English | Default. Best speed/quality ratio |
cross-encoder/ms-marco-MiniLM-L-12-v2 |
~130 MB | English | Higher quality |
BAAI/bge-reranker-v2-m3 |
~2.2 GB | 100+ | Best multilingual reranker |
BAAI/bge-reranker-base |
~1.1 GB | English | Balanced reranker |
BAAI/bge-reranker-large |
~1.3 GB | English | Highest accuracy |
jinaai/jina-reranker-v2-base-multilingual |
~1.1 GB | 100+ | Jina multilingual |
from DeepTextSearch import Reranker
# Tiny reranker for CPU / serverless / edge
reranker = Reranker("cross-encoder/ms-marco-TinyBERT-L-2-v2")
# Default balanced reranker
reranker = Reranker()
# Best multilingual reranker
reranker = Reranker("BAAI/bge-reranker-v2-m3")
# Local fine-tuned reranker
reranker = Reranker("./my-fine-tuned-reranker")Auto-detects the best available device, or set explicitly:
# Auto-detect (CUDA > MPS > CPU)
embedder = TextEmbedder()
# Force CPU
embedder = TextEmbedder(device="cpu")
# Force CUDA GPU
embedder = TextEmbedder(device="cuda")
# Force Apple Silicon GPU
embedder = TextEmbedder(device="mps")
# Same for reranker
reranker = Reranker(device="cuda")# Local fine-tuned embedding model
embedder = TextEmbedder("./my-fine-tuned-model")
# Local fine-tuned reranker
reranker = Reranker("./my-fine-tuned-reranker")
# Private HuggingFace model
embedder = TextEmbedder("your-org/your-private-model")search = TextSearch(embedder, mode="hybrid") # default
results = search.search("neural networks", top_n=5)
# Override mode per query
results = search.search("exact phrase match", mode="bm25")
results = search.search("conceptual similarity", mode="dense")
# Tune the balance
search = TextSearch(embedder, dense_weight=0.7, bm25_weight=0.3)
# Metadata filters (passed to vector store)
results = search.search("AI", top_n=10, filters={"category": "tech"})from DeepTextSearch import Reranker, RerankRequest
reranker = Reranker()
# Rerank search results
results = search.search("deep learning", top_n=20)
reranked = reranker.rerank_search_results("deep learning", results, top_n=5)
# Rerank any list of passages
request = RerankRequest(
query="efficient search",
passages=[
{"text": "FAISS enables billion-scale similarity search.", "id": 1},
{"text": "PostgreSQL supports full-text search.", "id": 2},
],
)
ranked = reranker.rerank(request)
# Rerank plain text strings
ranked = reranker.rerank_texts("query", ["text 1", "text 2", "text 3"])Save to any local folder path:
# Save to a specific folder
embedder.save("/path/to/my_index")
embedder.save("./projects/search_index")
embedder.save("~/my_indexes/v1")
# Load later (no re-embedding needed)
embedder = TextEmbedder.load("/path/to/my_index")
search = TextSearch(embedder)# From CSV
embedder = TextEmbedder.from_csv(
"articles.csv",
text_column="content",
metadata_columns=["title", "date", "category"],
)
# From DataFrame
import pandas as pd
df = pd.read_csv("articles.csv")
embedder = TextEmbedder()
embedder.index(df, text_column="content", metadata_columns=["title", "date"])# Add documents
embedder.add("New document about quantum computing.")
embedder.add(
["Another doc", "And another"],
metadata=[{"source": "web"}, {"source": "paper"}],
)
# Delete by index
embedder.delete([0, 5, 12])Complete Retrieval Augmented Generation pipeline:
from DeepTextSearch import TextEmbedder, TextSearch, Reranker
# Step 1: Embed & index your knowledge base
embedder = TextEmbedder(model_name="BAAI/bge-m3")
embedder.index(your_documents)
embedder.save("./knowledge_base")
# Step 2: Hybrid search (retrieve candidates)
search = TextSearch(embedder, mode="hybrid")
results = search.search("your query", top_n=20)
# Step 3: Rerank (refine top results)
reranker = Reranker()
context_docs = reranker.rerank_search_results("your query", results, top_n=5)
# Step 4: Feed to LLM
context = "\n".join([doc["text"] for doc in context_docs])
# Pass context + query to your LLM of choiceUse DeepTextSearch as a drop-in retriever in LangChain RAG chains:
from DeepTextSearch import TextEmbedder, Reranker
from DeepTextSearch.agents.langchain_retriever import create_langchain_retriever
# Build index
embedder = TextEmbedder()
embedder.index(your_documents)
# Create LangChain retriever
retriever = create_langchain_retriever(
embedder,
mode="hybrid",
reranker=Reranker(),
top_n=5,
)
# Use in a LangChain chain
from langchain_core.runnables import RunnablePassthrough
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
prompt = ChatPromptTemplate.from_template("Context: {context}\n\nQuestion: {question}")
llm = ChatOpenAI()
chain = {"context": retriever, "question": RunnablePassthrough()} | prompt | llm
answer = chain.invoke("What is machine learning?")Use DeepTextSearch as a retriever in LlamaIndex query engines:
from DeepTextSearch import TextEmbedder, Reranker
from DeepTextSearch.agents.llamaindex_retriever import create_llamaindex_retriever
# Build index
embedder = TextEmbedder()
embedder.index(your_documents)
# Create LlamaIndex retriever
retriever = create_llamaindex_retriever(
embedder,
mode="hybrid",
reranker=Reranker(),
top_n=5,
)
# Use in a query engine
from llama_index.core.query_engine import RetrieverQueryEngine
query_engine = RetrieverQueryEngine.from_args(retriever)
response = query_engine.query("What is machine learning?")Built-in MCP server for agentic AI integration:
# Start the MCP server
deep-text-search-mcp --index-path ./my_index
# With reranking
deep-text-search-mcp --index-path ./my_index --reranker-model cross-encoder/ms-marco-MiniLM-L-6-v2
# Force GPU
deep-text-search-mcp --index-path ./my_index --device cudaClaude Desktop config (claude_desktop_config.json):
{
"mcpServers": {
"text-search": {
"command": "deep-text-search-mcp",
"args": ["--index-path", "/path/to/my_index"]
}
}
}MCP Tools:
| Tool | Description |
|---|---|
search_texts(query, k, mode) |
Hybrid/dense/BM25 search over the indexed corpus |
rerank_passages(query, passages, top_n) |
Rerank passages by relevance |
get_index_info() |
Get corpus size, model, dimension, device info |
For any AI agent framework:
from DeepTextSearch import TextEmbedder, Reranker
from DeepTextSearch.agents import TextSearchTool
embedder = TextEmbedder()
embedder.index(your_texts)
tool = TextSearchTool(embedder, reranker=Reranker())
# Use as a function
results = tool("what is machine learning?", k=5)
# Get OpenAI/Claude function-calling schema
schema = tool.tool_definition| # | Demo | Description |
|---|---|---|
| 1 | Basic Search | Index a list of texts and search |
| 2 | Hybrid Search Modes | Compare hybrid, dense, and BM25 modes |
| 3 | Reranking | Cross-encoder reranking with different methods |
| 4 | Metadata Filtering | Store and filter by metadata |
| 5 | Save & Load Index | Persist and reload indexes |
| 6 | Incremental Indexing | Add and delete documents dynamically |
| 7 | CSV & DataFrame Loading | Load from CSV, DataFrame, Series, list |
| 8 | Multiple Models | Different embedding and reranker models |
| 9 | FAISS Index Types | Flat vs HNSW index comparison |
| 10 | RAG Pipeline | Complete retrieve → rerank → generate pipeline |
| 11 | Agent Tool | Callable tool for AI agents |
Interactive notebooks with complete, real-world examples — run directly in Google Colab:
| # | Case Study | Open |
|---|---|---|
| 1 | News Article Search & Recommendation | |
| 2 | RAG Pipeline — Technical Documentation Q&A | |
| 3 | E-Commerce Product Search & Recommendation |
For detailed documentation, see the Documents folder:
| # | Document | Description |
|---|---|---|
| 1 | Getting Started | Installation, quick start, core concepts |
| 2 | Embedding Models | Model selection, custom models, GPU/CPU |
| 3 | Search Engine | Hybrid, dense, BM25 search, tuning |
| 4 | Vector Stores | FAISS, ChromaDB, Qdrant, PostgreSQL, MongoDB |
| 5 | Reranking | Cross-encoder models, tiny to large |
| 6 | Agentic Integration | MCP, LangChain, LlamaIndex, agent tools |
| 7 | Data Loading | CSV, DataFrame, incremental indexing |
| 8 | API Reference | Complete API docs |
DeepTextSearch/
├── __init__.py # Exports: TextEmbedder, TextSearch, Reranker, etc.
├── config.py # Model presets, defaults, device auto-detection
├── embedder.py # Embedding + pluggable vector store indexing
├── searcher.py # Hybrid/dense/BM25 search + RRF fusion
├── reranker.py # Cross-encoder reranking
├── vectorstores/
│ ├── base.py # BaseVectorStore abstract interface
│ ├── faiss_store.py # FAISS (flat/ivf/hnsw) — default
│ ├── chroma_store.py # ChromaDB backend
│ ├── qdrant_store.py # Qdrant backend
│ ├── postgres_store.py # PostgreSQL + pgvector backend
│ └── mongo_store.py # MongoDB Atlas Vector Search backend
└── agents/
├── tool_interface.py # Generic agent tool (OpenAI/Claude function calling)
├── mcp_server.py # MCP server + CLI entry point
├── langchain_retriever.py # LangChain BaseRetriever wrapper
└── llamaindex_retriever.py # LlamaIndex BaseRetriever wrapper

Nilesh Verma Website |
If you use DeepTextSearch in your research or project, please cite it:
@software{verma2021deeptextsearch,
author = {Nilesh Verma},
title = {DeepTextSearch: AI-Powered Multilingual Text Search and Reranking Engine},
year = {2021},
publisher = {GitHub},
url = {https://github.com/TechyNilesh/DeepTextSearch},
version = {1.0.0}
}MIT License — Copyright (c) 2021-2026 Nilesh Verma