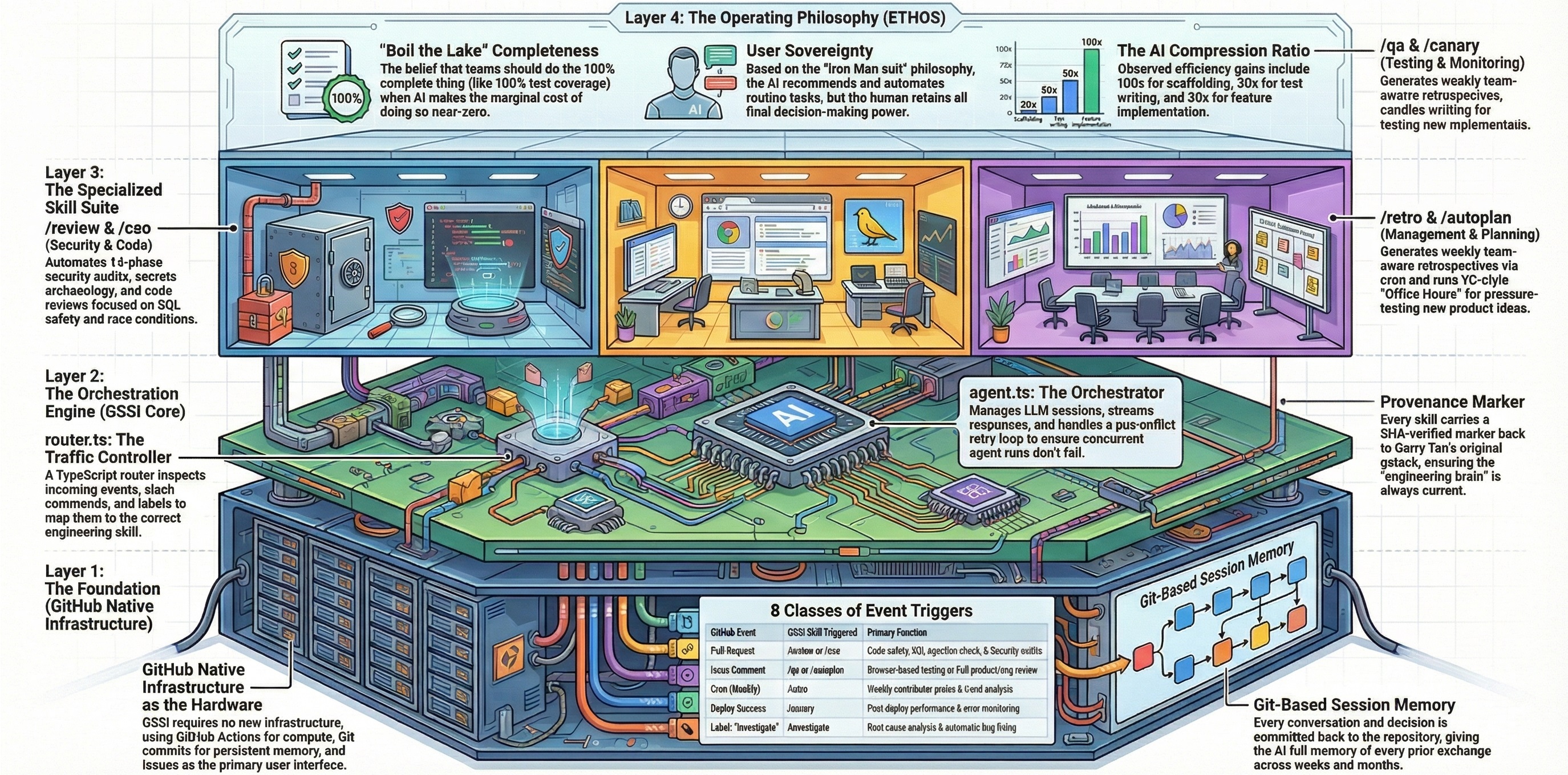
One command, fully reviewed plan out. Loads CEO, design, and engineering review skills and runs them sequentially with auto-decisions using 6 decision principles. Surfaces taste decisions at a final approval gate.
| Property | Value |
|---|---|
| Trigger | Comment /autoplan on an issue |
| Browser Required | No |
| Default State | ✅ Enabled |
| Results Path | Test plan artifact at .github-gstack-intelligence/state/results/$SLUG/, restore point saved to .github-gstack-intelligence/state/local/ |
- Create or open an issue containing your plan (or a link to a plan file).
- Comment
/autoplanon the issue. - The skill runs the full CEO → Design → Eng review pipeline automatically.
- Mechanical decisions are auto-decided silently. Taste decisions and User Challenges are surfaced at a final approval gate for your input.
Best for: When you have a plan file and want the full review gauntlet without answering 15–30 intermediate questions manually.
Tip: If you want to run individual reviews interactively, use /plan-ceo-review, /plan-design-review, or /plan-eng-review separately instead.
These rules auto-answer every intermediate question:
- Choose completeness — Ship the whole thing. Pick the approach that covers more edge cases.
- Boil lakes — Fix everything in the blast radius (files modified + direct importers). Auto-approve expansions that are in blast radius AND < 1 day effort (< 5 files, no new infra).
- Pragmatic — If two options fix the same thing, pick the cleaner one. 5 seconds choosing, not 5 minutes.
- DRY — Duplicates existing functionality? Reject. Reuse what exists.
- Explicit over clever — 10-line obvious fix > 200-line abstraction. Pick what a new contributor reads in 30 seconds.
- Bias toward action — Merge > review cycles > stale deliberation. Flag concerns but don't block.
Conflict resolution (context-dependent tiebreakers):
- CEO phase: Completeness + Boil lakes dominate.
- Eng phase: Explicit + Pragmatic dominate.
- Design phase: Explicit + Completeness dominate.
Every auto-decision is classified:
- Mechanical — One clearly right answer. Auto-decided silently. Examples: run evals (always yes), reduce scope on a complete plan (always no).
- Taste — Reasonable people could disagree. Auto-decided with recommendation but surfaced at the final gate. Sources: close approaches, borderline scope, codex disagreements.
- User Challenge — Both models agree the user's stated direction should change. NEVER auto-decided. Always presented at the final gate with: what the user said, what both models recommend, why, what context might be missing, and cost if wrong.
- Captures a restore point of the plan file before modifying anything.
- Reads context:
CLAUDE.md,TODOS.md, git log, design docs. - Detects UI scope to determine whether to run the Design phase.
- Loads skill files from disk for each review phase.
Follows the full plan-ceo-review methodology:
- Premise challenge (0A–0F) — the ONE question that is NOT auto-decided.
- All 10+ review sections at full depth.
- Dual voices: runs both Claude subagent and Codex for independent strategic assessment.
- Produces CEO consensus table, dream state delta, Error & Rescue Registry, Failure Modes Registry.
- Mode: SELECTIVE EXPANSION by default.
Runs only if UI scope was detected. Follows the full plan-design-review methodology:
- All 7 design dimensions rated 0–10.
- Dual voices for independent design assessment.
- Produces design litmus scorecard.
Follows the full plan-eng-review methodology:
- Scope challenge with actual code analysis.
- Architecture, Code Quality, Test, and Performance reviews.
- Dual voices for independent engineering assessment.
- Produces ASCII dependency graph, test diagram, test plan artifact.
Every auto-decision is logged as a row in the plan file:
| # | Phase | Decision | Classification | Principle | Rationale | Rejected |
|---|-------|----------|---------------|-----------|-----------|----------|After all phases complete, surfaces:
- All taste decisions with auto-decided recommendation and both-sides reasoning.
- All User Challenges with full context.
- Pre-gate verification ensures all required outputs were produced.
Identifies patterns that appeared across multiple review phases (e.g., a concern raised in CEO review that also appeared in engineering review).
## /autoplan — Fully Reviewed Plan
### Phase 1: CEO Review ✅
Mode: SELECTIVE EXPANSION
Premises: 3/3 confirmed by user
Codex: 2 concerns | Claude subagent: 3 issues
Consensus: 5/6 confirmed, 1 disagreement → surfaced at gate
### Phase 2: Design Review ✅ (UI scope detected)
Initial score: 4/10 → Final: 8/10
7 dimensions evaluated, 4 auto-fixed, 1 taste decision surfaced
### Phase 3: Engineering Review ✅
Architecture: 2 issues found, auto-resolved
Test coverage: 3 gaps identified, test plan written
Performance: 1 issue found (N+1 query), auto-fixed
### Decision Audit Trail
| # | Phase | Decision | Classification | Principle | Rationale |
|---|-------|--------------------|---------------|-------------|------------------------------|
| 1 | CEO | Accept premise #2 | Mechanical | P6 (action) | Evidence supports direction |
| 2 | Eng | Add index on users | Mechanical | P3 (pragmatic) | Obvious perf improvement |
| 3 | Design| Sidebar vs tabs | Taste | P5 (explicit) | Both viable, different UX |
### 🚦 Final Approval Gate
**Taste Decisions (1):**
1. Navigation: sidebar (auto-decided) vs. tabs — both viable...
**User Challenges (0):**
None — models agree with user's direction.In config.json:
{
"skills": {
"autoplan": {
"enabled": true,
"trigger": "issue_comment"
}
}
}| Field | Description |
|---|---|
enabled |
Whether the skill is active (true/false). |
trigger |
Event type — issue_comment means it fires when /autoplan is commented on an issue. |
- Browser: Not required.
- Model: Uses the model configured in
config.jsondefaults (currentlygpt-5.4). Benefits from dual-model setup (Claude + Codex) for independent outside voices. - Allowed tools: Bash, Read, Write, Edit, Glob, Grep, WebSearch.
- Benefits from: Prior
/office-hoursoutput for product context.
- Plan file — Updated in-place with review findings, decision audit trail, and required outputs.
- Restore point — Saved to
.github-gstack-intelligence/state/local/projects/$SLUG/for rollback. - Test plan — Written to
.github-gstack-intelligence/state/results/$SLUG/. - CEO plan — Written to
.github-gstack-intelligence/state/results/$SLUG/ceo-plans/(for EXPANSION/SELECTIVE EXPANSION modes). - TODOS.md — Updated with deferred items.
- Skill prompt:
../skills/autoplan.md - CEO review skill:
../skills/plan-ceo-review.md - Design review skill:
../skills/plan-design-review.md - Eng review skill:
../skills/plan-eng-review.md - Config:
../config.json - Router:
../lifecycle/router.ts
/plan-ceo-review— Run the CEO review interactively (standalone)/plan-eng-review— Run the engineering review interactively (standalone)/plan-design-review— Run the design review interactively (standalone)/plan-devex-review— Run the developer experience review interactively (standalone)/office-hours— Run before/autoplanto establish product direction