LiDAR semantic segmentation traditionally relies on fully supervised training, requiring large-scale labeled datasets that are expensive to acquire. Unlike images, self-supervised pre-training for LiDAR remains difficult due to limited data diversity and strong sensor-specific biases. Existing cross-modal transfer methods mitigate this gap by leveraging pre-trained image models, but still require training LiDAR backbones from scratch and tightly synchronized, accurately calibrated camera–LiDAR pairs.
BALViT overcomes these limitations by directly adapting frozen vision foundation models to LiDAR. We tailor only the patch embedding, decoder, and a lightweight 2D–3D adapter, enabling seamless integration of LiDAR geometry into a pre-trained ViT. Through bidirectional feature exchange between range-view and BEV representations inside the frozen backbone, BALViT preserves the amodal reasoning capabilities of vision transformers while drastically reducing the need for labeled LiDAR data.
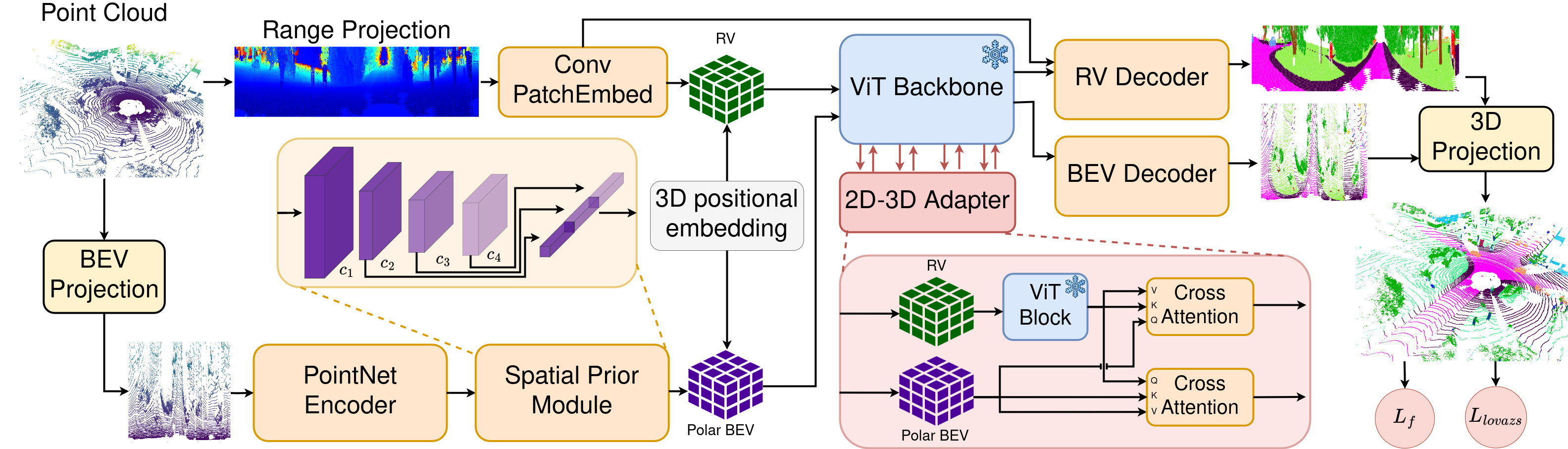
This repository contains the PyTorch re-implementation of our IROS 2025 paper Label-Efficient LiDAR Semantic Segmentation with 2D-3D Vision Transformer Adapters.
If you find this code useful for your research, we kindly ask you to consider citing our papers:
@article{hindel2025label,
title={Label-Efficient LiDAR Semantic Segmentation with 2D-3D Vision Transformer Adapters},
author={Hindel, Julia and Mohan, Rohit and Bratulic, Jelena and Cattaneo, Daniele and Brox, Thomas and Valada, Abhinav},
journal={arXiv preprint arXiv:2503.03299},
year={2025}
}
- Linux
- Python 3.9
- PyTorch 2.4
- CUDA 11.7
- GCC 7 or higher
IMPORTANT NOTE: These requirements are not necessarily mandatory. However, we have only tested the code under the above settings and cannot provide support for other setups.
We provide a pre-configured Conda environment with all required dependencies.
conda env create -f environment.yaml
conda activate balvitThe Deformable Attention module must be compiled before running the code.
cd balvit/models/vit_adapter/ops
sh make.sh
cd -- Download the dataset from the official website.
- Organize the directory as:
$DATA_ROOT/
└── sequences/
├── 00/
├── 01/
├── ...
└── 21/
- Place label files under each sequence directory following the official SemanticKITTI format.
Follow the official nuScenes LiDAR semantic segmentation preprocessing instructions and ensure the converted files are stored under:
$DATA_ROOT/
└── nuscenes/
├── lidarseg/
└── samples/
To train the model:
torchrun --nproc_per_node=$NUM_GPUS --master_addr=127.0.0.1 --master_port=30322 \
main.py \
$CONFIG_FILE \
--data_root=$DATA_ROOT \
--save_path=$SAVE_PATHParameters:
$NUM_GPUS: Number of GPUs to use$CONFIG_FILE: Path to config file (e.g.,config/kitti.yaml)$DATA_ROOT: Path to dataset sequences directory$SAVE_PATH: Directory to save checkpoints and logs
Example:
torchrun --nproc_per_node=1 --master_addr=127.0.0.1 --master_port=30322 \
main.py \
config/kitti.yaml \
--data_root=/path/to/semantickitti/dataset/sequences \
--save_path=./outputTo evaluate a trained model:
torchrun --nproc_per_node=$NUM_GPUS --master_addr=127.0.0.1 --master_port=30322 \
main.py \
$CONFIG_FILE \
--data_root=$DATA_ROOT \
--save_path=$SAVE_PATH \
--test_only \
--checkpoint $CHECKPOINT_PATHParameters:
$NUM_GPUS: Number of GPUs to use$CONFIG_FILE: Path to config file (e.g.,config/kitti.yaml)$DATA_ROOT: Path to dataset sequences directory$SAVE_PATH: Directory to save evaluation results$CHECKPOINT_PATH: Path to trained model checkpoint--test_only: Flag to run evaluation only
Example:
torchrun --nproc_per_node=8 --master_addr=127.0.0.1 --master_port=30322 \
main.py \
config/kitti/kitti_1.yaml \
--data_root=/path/to/semantickitti/dataset/sequences \
--save_path=./eval_results \
--test_only \
--checkpoint ./checkpoints/skitti_1.pth| Model | mIoU | Download |
|---|---|---|
| SemanticKITTI 1% | 51.87 | checkpoint |
| nuScenes 1% | 59.30 | checkpoint |
We have used utility functions from other open-source projects. We especially thank the authors of:
For academic usage, the code is released under the GPLv3 license. For any commercial purpose, please contact the authors.