The complete methodology for using GStack Intelligence as a systematic engineering practice. Not a tool reference — a discipline.
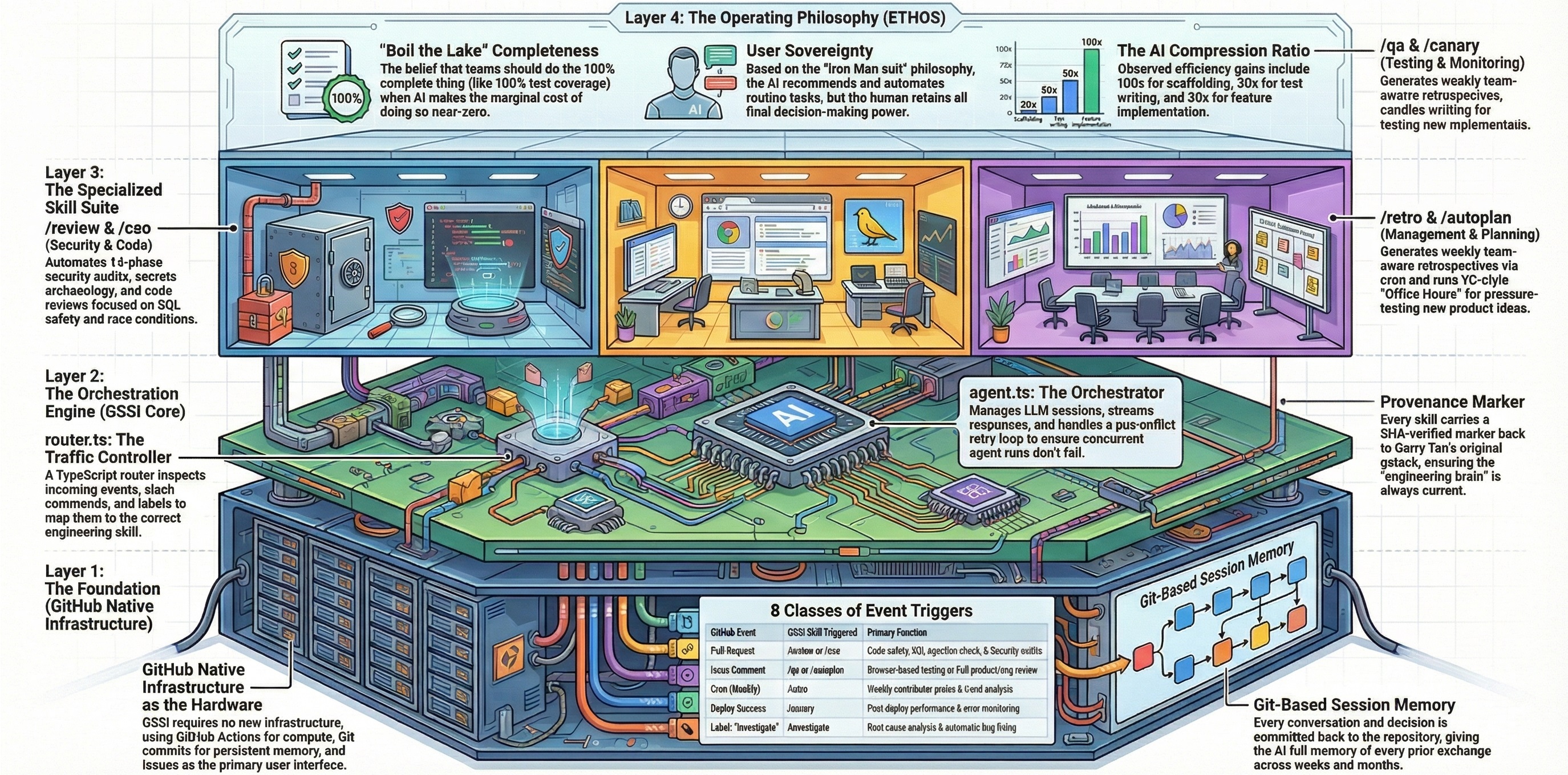
GStack Intelligence is not a collection of independent tools. It is a system — a tightly integrated engineering practice where each command is a specialist operating within a larger discipline. You do not use GStack Intelligence by picking a command from a menu. You use it by following The Method: a sequence of phases, each building on the last, each enforcing quality gates that compound into software excellence.
Every command is powerful alone. But the real leverage — the kind that turns a solo developer into a force multiplier and a team into a shipping machine — comes from using them together, in the right order, with the right discipline.
The Method encodes the engineering practices of Garry Tan, CEO of Y Combinator, into a repeatable system any developer can follow. These are not abstract principles. They are battle-tested practices from decades of building, investing in, and advising the world's most successful startups — distilled into commands you can run today.
Three principles from the ETHOS form the philosophical foundation of everything that follows:
The marginal cost of completeness is near-zero with AI. When an AI agent can generate a comprehensive security audit in seconds, there is no excuse for a shallow one. When a design review can check seven dimensions instead of two, check all seven. When a test suite can cover edge cases that would take a human hours to enumerate, enumerate them all.
"Good enough" is the enemy of excellence when the cost of excellence is nearly free. Do the complete thing.
Every problem you face has likely been solved before — often multiple times, in multiple ways, at multiple levels of maturity. The Method enforces a three-layer knowledge search before any new construction:
- Layer 1: Tried-and-True — Established solutions with years of production hardening. Battle-tested. Boring. Usually correct.
- Layer 2: New-and-Popular — Emerging approaches gaining traction. Modern. Exciting. Needs evaluation.
- Layer 3: First-Principles — Novel solutions derived from fundamental reasoning. Original. Risky. Sometimes brilliant.
The Eureka Moment is when you find the right solution at the right layer. Sometimes it's a well-known library. Sometimes it's a new pattern. Sometimes — rarely — it's something genuinely new. The Method helps you search systematically so you don't waste time reinventing what already exists, and you don't miss what's genuinely better.
AI recommends. Humans decide. This is not a philosophical nicety — it is a structural requirement of The Method.
Every GStack Intelligence command operates within a generation-verification loop: the AI generates analysis, recommendations, and sometimes code — but it surfaces decisions explicitly. Items marked ASK require human judgment. Items marked USER CHALLENGE cannot be auto-decided. The system is designed to amplify your judgment, not replace it.
You are sovereign over your codebase. The Method gives you better information, faster analysis, and more complete coverage — but the decisions are always yours.
Every feature, every project, every product should flow through five phases. Skipping a phase does not save time — it moves the cost downstream where it compounds into rework, bugs, and missed opportunities.
Before any code. Before any plan. Understand the problem.
This is where most projects fail — not in implementation, but in understanding. Teams build the wrong thing, solve a problem no one has, or miss the real opportunity hiding behind the obvious one.
The /office-hours command initiates a structured diagnostic session modeled on Y Combinator office hours — the same format that has helped launch thousands of successful startups.
Startup Mode — When you're building something new or evaluating product-market fit:
- Is there real demand? Not "would people like this?" but "are people already trying to solve this with duct tape and workarounds?"
- Who is the specific user? Not a demographic segment — a real person with a real name, a real job, and a real pain point.
- What is the narrowest wedge? The smallest possible version that delivers undeniable value to that specific user. Not an MVP — a wedge. MVPs are often too big.
- What does "interest is not demand" mean for this idea? People saying "that sounds cool" is not evidence. People paying money, signing up for waitlists, or building ugly spreadsheet workarounds — that's evidence.
Builder Mode — When you're building for the joy of building:
- What's the coolest version? Not the most practical — the version that makes someone say "whoa."
- What's the demo moment? The single interaction that, when shown to another developer, makes them want to try it.
- What makes this technically fascinating? The engineering challenge that makes this worth building even if no one else uses it.
Output: A design document with a clear problem statement, demand evidence (or inspiration rationale), and a recommended approach. This document becomes the input to Phase 2.
Key Principle: "Interest is not demand." Evidence-based product thinking separates builders who ship products people use from builders who ship products people politely ignore.
Planning is not bureaucracy. It is the highest-leverage activity in software development. One hour of planning saves ten hours of implementation and a hundred hours of debugging.
The Method uses three specialized reviews, each catching different classes of issues that the others miss. Run them in order. The order matters.
The CEO review challenges premises, not just plans. It asks the questions that founders and engineering leaders ask:
- Four Scope Modes: Evaluates the plan at four different ambition levels — from minimum viable to maximum audacious — and helps you choose the right scope for your current stage.
- 14 Cognitive Patterns of Great CEOs: Applies mental models drawn from the decision-making patterns of exceptional leaders: first-principles thinking, inversion, second-order effects, opportunity cost analysis, and more.
- Dream State Mapping: What does the ideal end state look like? Not the next milestone — the destination. Working backward from the dream state reveals steps you would otherwise miss.
- Failure Modes Registry: Systematic enumeration of how this plan could fail. Not just technical failures — market failures, timing failures, team failures, motivation failures.
What it catches: Wrong problem. Wrong scope. Wrong timing. Wrong audience. Misaligned incentives. Premature optimization. Missing the forest for the trees.
The design review evaluates the plan across seven dimensions, each rated 0-10:
- Information Architecture — Is the content hierarchy logical? Can users find what they need?
- Interaction States — Are all states specified? Empty, loading, error, success, partial, overflow?
- Responsive Design — Does the design work across screen sizes and input methods?
- Accessibility — WCAG compliance, screen reader compatibility, keyboard navigation, color contrast?
- Visual Consistency — Does the design follow the existing design system? Are patterns reused?
- User Flow Completeness — Are all paths through the feature specified? Happy path, error paths, edge cases?
- AI Slop Detection — Does the design contain vague, hand-wavy descriptions that sound impressive but specify nothing? "Intuitive interface" is AI slop. "Three-tab navigation with search, favorites, and recent items" is a specification.
What it catches: Missing states. Accessibility violations. Responsive breakpoints. Empty state designs. Error handling gaps. Vague specifications that will cause implementation ambiguity.
The engineering review evaluates the plan for implementability and technical soundness:
- Dependency Graphs — What depends on what? What can be parallelized? What's on the critical path?
- Test Coverage Maps — What needs to be tested? Unit, integration, end-to-end? What are the test boundaries?
- Performance Analysis — Where are the potential bottlenecks? What are the latency budgets? What scales and what doesn't?
- Failure Path Coverage — What happens when the database is slow? When the API is down? When the user's network drops? When the payload is 10x expected size?
What it catches: Missing error handling. Unacknowledged dependencies. Performance cliffs. Untestable designs. Implicit assumptions about the runtime environment.
The /autoplan command runs all three reviews automatically — CEO, Design, and Engineering — making auto-decisions using six decision principles (detailed in the Decision Framework section below).
The key innovation of /autoplan is the taste gate: it identifies decisions that require human judgment — aesthetic choices, product direction, scope trade-offs — and surfaces them at a final approval gate. Everything else is decided automatically based on the six principles.
This is The Method's answer to "I don't have time for three reviews." You do — because the AI runs them for you. You only need to make the decisions that actually require your taste and judgment.
Before implementation, /design-consultation builds a complete design system:
- Typography — Font families, sizes, weights, line heights, letter spacing. A complete type scale.
- Color — Primary, secondary, accent, semantic (success, warning, error, info), neutral scales. Dark mode variants.
- Layout — Grid system, breakpoints, container sizes, page templates.
- Spacing — A spacing scale (4px base, or 8px base) applied consistently.
- Motion — Animation timing, easing curves, transition types, reduced-motion alternatives.
Why before implementation: Decisions about typography, color, and spacing made during implementation are always worse than decisions made deliberately beforehand. A design system prevents the slow drift toward visual inconsistency that plagues every project without one.
CEO → Design → Engineering. Strategy before aesthetics before architecture.
Why? Because a brilliant architecture for the wrong product is waste. A beautiful design for an ill-scoped feature is waste. Strategy sets the boundaries. Design fills the boundaries with user-facing specification. Engineering makes the specification real. Reverse the order and you optimize locally while failing globally.
With a reviewed plan in hand, implementation begins. The Method does not prescribe how you write code — it prescribes quality gates that catch issues before they compound.
The plan from Phase 2 is not a suggestion. It is a specification. Deviation from the plan should be conscious and documented, not accidental and silent.
When you open a pull request, /review runs automatically. It performs a structured checklist review covering:
- SQL injection — Parameterized queries, ORM usage, raw query safety
- Race conditions — Concurrent access patterns, lock ordering, atomic operations
- LLM trust boundaries — Prompt injection vectors, output sanitization, model output validation
- Enum completeness — Switch/match exhaustiveness, missing cases, default handling
- Error handling — Catch completeness, error propagation, user-facing error messages
- Test coverage — New code covered by tests, edge cases tested, regression tests added
Each finding is classified as FIX (do this), ASK (decide this), or REPORT (know this). The classification respects User Sovereignty — the system tells you what it found and how confident it is, but you decide what to do.
For security-sensitive changes, add the security-audit label to your PR. This triggers the /cso command — a 14-phase Chief Security Officer audit that goes far beyond basic code review:
- Authentication and authorization
- Input validation and sanitization
- Cryptographic practices
- Session management
- API security
- Data protection and privacy
- Dependency vulnerabilities
- Deployment security
- Logging and monitoring
- Error handling and information leakage
- Business logic security
- Client-side security
- Supply chain security
- Compliance and regulatory alignment
This is not a linter. It is a structured security audit that a CISO would perform — automated and repeatable.
For UI changes, add the design-review label. This triggers a visual design audit with automated fixes — catching spacing inconsistencies, color misuse, typography violations, and accessibility issues.
When bugs surface, add the investigate label to the issue. This triggers systematic root-cause debugging governed by The Iron Law: no fixes without root cause investigation first.
The investigation produces:
- A root cause analysis (not just "what broke" but "why it broke")
- A fix that addresses the cause, not the symptom
- A regression test that prevents recurrence
- A timeline of how the bug was introduced
Code that passes review is not code that's ready to ship. Code that works for users in a real browser on a real network is ready to ship.
The /qa command opens a real browser, navigates your application like a real user, and finds bugs that automated tests miss:
- Visual regressions
- Broken interactions
- Missing loading states
- Error states that show stack traces
- Responsive layout breakdowns
- Accessibility failures
- Performance issues visible to users
When it finds bugs, it fixes them — creating atomic commits for each fix. Each commit is a single, reviewable change.
The same comprehensive testing as /qa, but report-only. Use this when you want to understand the quality landscape without auto-fixes — for example, when evaluating a codebase you've inherited or reviewing a colleague's work.
The /ship command is the culmination of The Method. It executes the complete shipping sequence:
- Merge — Integrate the feature branch
- Test — Run the full test suite
- Review — Final automated review pass
- Version — Semantic version bump (asks before bumping — never auto-decides)
- Changelog — Generate changelog from commits
- Commit — Create the release commit
- Push — Push to remote
- PR — Create or update the pull request
- Docs — Trigger documentation sync
One command. The entire release pipeline. Every step verified, every artifact generated, every gate passed.
Key constraint: /ship will not complete if verification evidence is stale. It requires fresh evidence — not "the tests passed yesterday" but "the tests passed in this pipeline run." No completion claims without fresh verification evidence.
Automatically invoked by /ship, the /document-release command ensures documentation stays synchronized with the codebase:
- Updates API documentation
- Syncs README files
- Updates version references
- Generates migration guides when needed
Key constraint: Never bumps VERSION without asking. Documentation is generated from code, but version decisions are human decisions.
Shipping is not the end. Shipping is the beginning of learning.
Every Friday (or whenever you choose), /retro analyzes your engineering practice:
- Commit Analysis — Volume, frequency, size distribution, message quality
- Session Detection — Identifies deep work sessions vs. scattered context-switching
- Trend Tracking — Week-over-week changes in velocity, quality, and focus
- Team Breakdowns — Per-contributor analysis (for team repos)
- Streak Counting — Consecutive days of shipping, reviewing, or testing
The retro is not a performance review. It is a mirror. It shows you what you actually did — not what you think you did — so you can make conscious adjustments.
Performance degrades gradually, then suddenly. /benchmark tracks Core Web Vitals over time:
- Largest Contentful Paint (LCP)
- First Input Delay (FID) / Interaction to Next Paint (INP)
- Cumulative Layout Shift (CLS)
- Time to First Byte (TTFB)
- Total Blocking Time (TBT)
The key insight: absolute performance numbers matter less than trends. A page that loads in 2.1 seconds is fine. A page that loaded in 1.8 seconds last week and loads in 2.1 seconds this week has a regression. /benchmark catches regressions before users notice them.
After every deploy, /canary monitors production with alert-on-change, not alert-on-absolute:
- If response times increase by more than a threshold: alert
- If error rates increase: alert
- If new error types appear: alert
- If availability drops: alert
The philosophy: your production baseline is your production baseline. Changes from that baseline — in either direction — are worth knowing about. Absolute thresholds ("alert if response time > 500ms") miss regressions in fast applications and generate noise in slow ones.
Theory is useful. Practice is essential. Here is how a feature flows through all five phases of The Method, from idea to production monitoring.
Open an issue: "Add real-time collaboration"
Add the office-hours label. The /office-hours command runs a product diagnostic:
- Is there real demand? Check support tickets. Are users already sharing notes via copy-paste? Are they requesting "Google Docs but for our app"? Are competitors shipping collaboration features?
- Who is the specific user? Sarah, a product manager at a 12-person startup, who currently copies notes into Slack after every meeting because her team can't see them in real-time.
- What's the narrowest wedge? Not full Google Docs. Not even real-time cursors. Just: two people can see each other's changes within 3 seconds. Live presence indicators. That's it.
Output: A design document that says: "Real-time sync with 3-second latency, presence indicators, optimistic local updates. Target user: small team leads who currently share notes manually."
Comment /autoplan on the design document. The automated pipeline runs:
CEO Review identifies:
- Scope risk: "Real-time" can expand to include cursors, comments, permissions, conflict resolution, offline support. Lock scope to sync + presence.
- Market timing: Competitors have this. It's table stakes, not differentiator. Ship fast, don't over-invest.
- Failure mode: If sync latency exceeds 5 seconds, the feature feels broken. Latency is the critical metric.
Design Review identifies:
- Missing states: What does the UI show when another user is typing? When connection drops? When there's a conflict?
- Accessibility gap: Presence indicators use only color (red/green dots). Need text labels for color-blind users.
- Mobile gap: No specification for how presence works on small screens.
Engineering Review identifies:
- WebSocket dependency: Need to evaluate Socket.IO vs. native WebSockets vs. a managed service.
- CRDT vs. OT: Conflict resolution strategy not specified. Recommend CRDT for simplicity at this scale.
- Test strategy gap: No plan for testing concurrent edits. Need a multi-client test harness.
The /autoplan taste gate surfaces one decision: "Should presence show user avatars or just colored dots?" This is a taste decision — the system can't auto-decide it. You choose: avatars.
Create branch feature/realtime-collab. Implement the plan:
- WebSocket server with CRDT-based sync
- Presence indicators with avatars and text labels
- Optimistic local updates with server reconciliation
- Connection drop handling with reconnection logic
Open a pull request. /review runs automatically and finds:
FIX: WebSocket connection doesn't validate auth token on upgradeASK: Should reconnection use exponential backoff or fixed interval?REPORT: The CRDT library is 45KB gzipped — within budget but worth noting
Fix the auth issue. Choose exponential backoff. Acknowledge the bundle size.
Add security-audit label. /cso runs and finds:
- WebSocket messages are not rate-limited — potential DoS vector
- Presence data leaks email addresses to other users — privacy concern
- CRDT merge operations are not validated server-side — potential data corruption vector
Fix all three. Run /qa https://staging.myapp.com:
- Finds: Presence indicator doesn't disappear when a user closes their tab (only on page navigation)
- Finds: On slow connections, optimistic updates flash briefly before server reconciliation
- Finds: Cursor jumps to end of document after sync on mobile Safari
Three bugs found, three atomic commits created, each with a fix and a test.
Comment /ship. The pipeline runs:
- Tests pass (including new multi-client concurrent edit tests)
- Review clean (all FIX items resolved)
- Version bumped from 2.3.1 to 2.4.0 (new feature = minor bump)
- Changelog generated
- PR created with full release notes
/document-releaseupdates API docs with new WebSocket endpoints
After deploy, /canary https://myapp.com monitors:
- WebSocket connection success rate: 99.2% (baseline: N/A, new feature)
- Sync latency p50: 1.2s, p99: 2.8s (under 3s target)
- Memory usage: +12MB per active session (within budget)
Friday: /retro shows:
- 47 commits over 8 days
- 3 deep sessions (4+ hours focused on collab feature)
- Test LOC ratio: 34% (above 30% threshold)
- Fix ratio: 28% (healthy — most code was new feature, not fixes)
The feature is live, monitored, documented, and measured. The Method is complete.
The Method is opinionated. When faced with ambiguity, these principles resolve it.
These principles guide every automated decision in The Method. When /autoplan encounters a choice it can auto-resolve, it applies these principles in order:
-
Choose completeness — When in doubt, do more. Handle the edge case. Add the test. Cover the error path. The marginal cost is near-zero.
-
Boil lakes — Do the comprehensive thing. Don't check three of seven dimensions — check all seven. Don't audit five of fourteen security phases — audit all fourteen.
-
Pragmatic — Completeness within reason. If a comprehensive approach would take 10x longer with 1% more coverage, be pragmatic. The goal is excellence, not perfection theater.
-
DRY — Don't Repeat Yourself. If a pattern exists, reuse it. If a utility exists, use it. If a convention is established, follow it. Duplication is a maintenance tax that compounds.
-
Explicit over clever — Code that is obvious is better than code that is elegant. A three-line
if/elseis better than a one-line ternary-inside-a-ternary. Debugging clever code costs more than writing explicit code. -
Bias toward action — When analysis is complete, act. Don't deliberate endlessly. Ship, measure, iterate. A good decision now beats a perfect decision next month.
These are not guidelines. They are laws. Breaking them breaks The Method.
-
No fixes without root cause investigation first (
/investigate) — Fixing symptoms creates new bugs. Fixing causes creates lasting solutions. The investigation must complete before the fix begins. -
No completion claims without fresh verification evidence (
/ship) — "It worked when I tested it Tuesday" is not evidence. Evidence is a test suite that passed in this pipeline run, a QA session that found no issues in this build, a benchmark that shows no regressions from this deploy. -
Never bump VERSION without asking (
/document-release) — Version numbers are semantic. They communicate meaning to users, package managers, and deployment systems. Automated systems must not change them without human approval. -
Never auto-decide User Challenges (
/autoplan) — Some decisions require taste, context, or domain knowledge that AI does not have. These are surfaced as User Challenges and must be decided by a human. The system will not proceed without your answer.
Every finding in The Method is classified by confidence:
| Tier | Meaning | Action |
|---|---|---|
| HIGH | The system is confident this is correct | Auto-fix immediately. No human approval needed. |
| MEDIUM | The system believes this is likely correct | Ask before fixing. Present the finding, the proposed fix, and the rationale. Human approves or rejects. |
| LOW | The system has identified something worth noting | Report only. No fix proposed. Human investigates if interested. |
This tiering is how The Method implements User Sovereignty in practice. High-confidence fixes don't waste your time with questions. Low-confidence findings don't waste your time with false positives. Medium-confidence findings respect your judgment.
A practical decision tree for every situation you'll encounter:
| I need to... | Use this command |
|---|---|
| Understand if my idea has real demand | /office-hours (Startup mode) |
| Brainstorm and explore a fun idea | /office-hours (Builder mode) |
| Review a plan strategically | /plan-ceo-review |
| Review a plan for design completeness | /plan-design-review |
| Review a plan for engineering rigor | /plan-eng-review |
| Get all three reviews at once | /autoplan |
| Build a design system | /design-consultation |
| Review code on a PR | /review (automatic) |
| Audit security deeply | /cso + security-audit label |
| Debug a production bug | /investigate + investigate label |
| Test a web app and fix bugs | /qa [url] |
| Test a web app without changing code | /qa-only [url] |
| Audit visual design and fix issues | /design-review + design-review label |
| Ship a feature branch | /ship |
| Update docs after a release | /document-release (automatic) |
| Analyze team velocity and quality | /retro |
| Detect performance regressions | /benchmark [url] |
| Monitor production after deploy | /canary [url] |
Rules of thumb:
- If you're not sure where to start:
/office-hours - If you have a plan but haven't reviewed it:
/autoplan - If you have code but haven't tested it:
/qa - If you want to ship:
/ship - If you want to improve:
/retro
The Method is a pipeline. Each command feeds into the next. Here is how they connect:
/office-hours ──▶ /autoplan ─┬─▶ /plan-ceo-review
├─▶ /plan-design-review
└─▶ /plan-eng-review
│
/design-consultation
│
▼
Implementation
│
▼
┌─────────────────────────────────────┐
│ Pull Request Events │
│ ┌─────────┐ ┌─────┐ ┌──────────────┐│
│ │/review │ │/cso │ │/design-review││
│ │(auto) │ │(label)│ │(label) ││
│ └─────────┘ └─────┘ └──────────────┘│
└─────────────────────────────────────┘
│
/qa or /qa-only
│
/ship
│
/document-release
│
/canary
│
/retro (weekly)
│
/benchmark (daily)
Reading the map:
- Arrows (
──▶) show flow: the output of one command is the input of the next. - The Pull Request box shows three commands that can run concurrently on any PR.
/reviewis automatic./csoand/design-revieware triggered by labels./qaand/shipare manual commands — you invoke them when you're ready./canary,/retro, and/benchmarkare operational — they run continuously after shipping.
Things that break The Method. If you find yourself doing any of these, stop and reconsider.
What it looks like: Jumping straight to code without /office-hours. Opening your editor before opening a conversation about what you're building and why.
Why it's dangerous: You build the wrong thing faster. Implementation speed is not valuable when aimed at the wrong target. A day spent in discovery saves a week of implementation, a month of maintenance, and the quiet death of a feature no one uses.
The fix: Start every project with /office-hours. Even if you think you know what to build. Especially if you think you know what to build.
What it looks like: Writing a plan document but never running /autoplan. Treating the plan as a formality — something you write because process requires it, not something you stress-test.
Why it's dangerous: Unreviewed plans contain scope creep, design gaps, and engineering risks that you won't discover until implementation — when they're 10x more expensive to fix.
The fix: Run /autoplan on every plan. It takes minutes. It catches issues that save days.
What it looks like: Using /ship without running /qa first. Trusting that passing tests means a working product.
Why it's dangerous: Tests verify that code does what the code says it should do. QA verifies that the product does what the user needs it to do. These are different things. A test suite with 100% coverage can still ship a product with broken user flows, visual regressions, and accessibility failures.
The fix: Run /qa before /ship. Always. The five minutes it takes will save you from the support ticket that arrives at 2 AM.
What it looks like: Running /review but ignoring ASK items. Seeing the findings, feeling vaguely concerned, and merging anyway.
Why it's dangerous: The system found issues and explicitly asked for your judgment. Ignoring them is not a neutral act — it's a decision to ship known risks without evaluation.
The fix: Address every ASK item. The answer can be "this is acceptable because [reason]" — but the answer cannot be silence.
What it looks like: Never running /retro. Shipping continuously but never pausing to ask "how are we doing?"
Why it's dangerous: Without measurement, you can't improve. You can't distinguish between a productive week and a scattered one. You can't identify patterns — the recurring bug types, the chronic context-switching, the slowly declining test coverage — until they become crises.
The fix: Run /retro every Friday. It takes two minutes to run and five minutes to read. The insights compound over weeks and months.
What it looks like: Using /qa once in isolation. Running /review on one PR. Trying /office-hours once to see what it does. Treating GStack Intelligence as a collection of independent tools.
Why it's dangerous: Individual commands are useful. The Method is transformative. The difference is the same as between doing one push-up and following a training program. The individual action has marginal value. The system has compounding value.
The fix: Commit to The Method. All five phases. Every feature. The discipline is the leverage.
How to know if The Method is working. These are not aspirational targets — they are achievable baselines that The Method is designed to produce.
| Metric | Target | Tracked By | Why It Matters |
|---|---|---|---|
| Test LOC Ratio | > 30% | /retro |
Code without tests is code you're afraid to change. 30% is the minimum for confident refactoring. |
| Fix Ratio | < 40% | /retro |
If more than 40% of your commits are fixes, you're not catching issues early enough. More review, less rework. |
| Deep Sessions | > 3/week | /retro |
Deep work (4+ hours of focused implementation) is where real progress happens. Fewer than 3 per week means too much context-switching. |
| Performance Grade | ≥ B | /benchmark |
Core Web Vitals grade. Below B means users are experiencing meaningful performance issues. |
| Canary Status | HEALTHY | /canary |
After every deploy, production should be healthy. Any other status means the deploy introduced a regression. |
| Review Results | Clean | /review |
Before every ship, all FIX items resolved, all ASK items addressed. No open issues. |
| Plan Completion | > 90% | /ship |
If your implementation covers less than 90% of the plan, you're either shipping incomplete features or your plans are too ambitious. |
Interpreting the numbers:
- If your test LOC ratio is below 30%, run
/qamore aggressively. It generates tests as part of its fixes. - If your fix ratio is above 40%, run
/autoplanmore thoroughly. Catching issues in planning is cheaper than catching them in production. - If your deep sessions are below 3/week, protect your calendar. The Method can't help if you don't have time to use it.
- If your performance grade is below B, run
/benchmarkdaily until you identify and fix the regression. - If your canary is unhealthy, run
/investigateimmediately. The Iron Law applies: no fixes without root cause investigation.
- Command Reference — All 26 commands with detailed specifications
- Workflows Guide — Step-by-step recipes for common scenarios
- Getting Started — Your first day with GStack Intelligence
- ETHOS — The builder principles behind every skill